If you are delivering high-stakes tests in linear forms – or piloting a bank for CAT/LOFT – you are faced with the issue of how to equate the forms together. That is, how can we defensibly translate a score on Form A to a score on Form B? While the concept is simple, the methodology can be complex, and there is an entire area of psychometric research devoted to this topic. There are a number of ways to approach this issue, and IRT equating is the strongest.
Why do we need equating?
The need is obvious: to adjust for differences in difficulty to ensure that all examinees receive a fair score on a stable scale. Suppose you take Form A and get s score of 72/100 while your friend takes Form B and gets a score of 74/100. Is your friend smarter than you, or did his form happen to have easier questions? Well, if the test designers built-in some overlap, we can answer this question empirically.
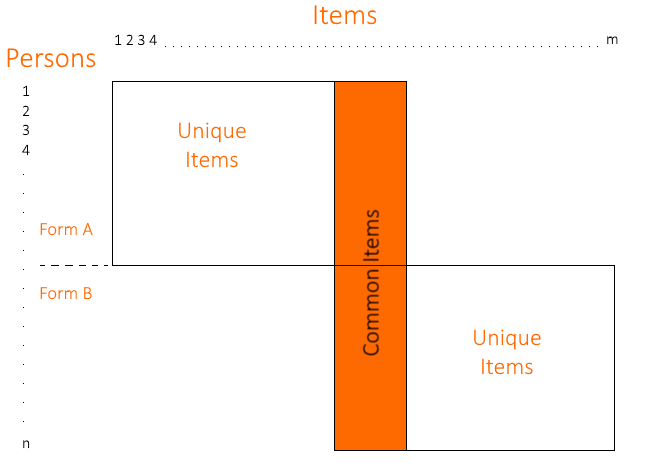
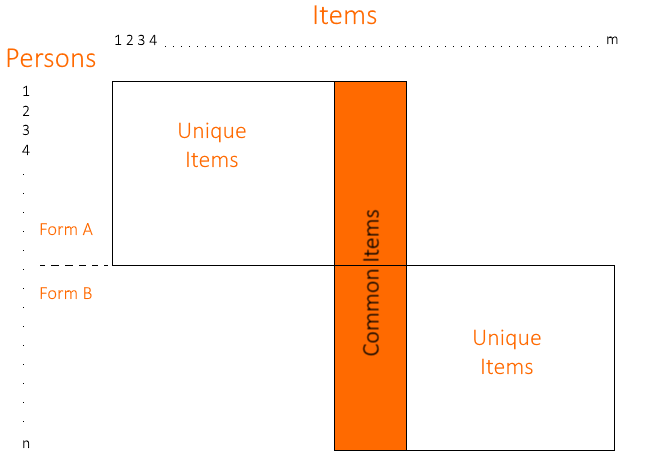
Suppose the two forms overlap by 50 items, called anchor items or equator items. Both forms are each delivered to a large, representative sample. Here are the results.
Form
Mean score on 50 overlap items
Mean score on 100 total items
A
30
72
B
30
74
Because the mean score on the anchor items was higher, we then think that the Form B group was a little smarter, which led to a higher total score.
Now suppose these are the results:
Form
Mean score on 50 overlap items
Mean score on 100 total items
A
32
72
B
32
74
Now, we have evidence that the groups are of equal ability. The higher total score on Form B must then be because the unique items on that form are a bit easier.
How do I calculate an equating?
You can equate forms with classical test theory (CTT) or item response theory (IRT). However, one of the reasons that IRT was invented was that equating with CTT was very weak. CTT methods include Tucker, Levine, and equipercentile. Right now, though, let’s focus on IRT.
IRT equating
There are three general approaches to IRT equating. All of them can be accomplished with our industry-leading software Xcalibre, though conversion equating requires an additional software called IRTEQ.
Conversion
Concurrent Calibration
Fixed Anchor Calibration
Conversion
With this approach, you need to calibrate each form of your test using IRT, completely separately. We then evaluate the relationship between IRT parameters on each form and use that to estimate the relationship to convert examinee scores. Theoretically what you do is line up the IRT parameters of the common items and perform a linear regression, so you can then apply that linear conversion to scores.
But DO NOT just do a regular linear regression. There are specific methods you must use, including mean/mean, mean/sigma, Stocking & Lord, and Haebara. Fortunately, you don’t have to figure out all the calculations yourself, as there is free software available to do it for you: IRTEQ.
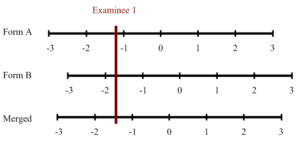
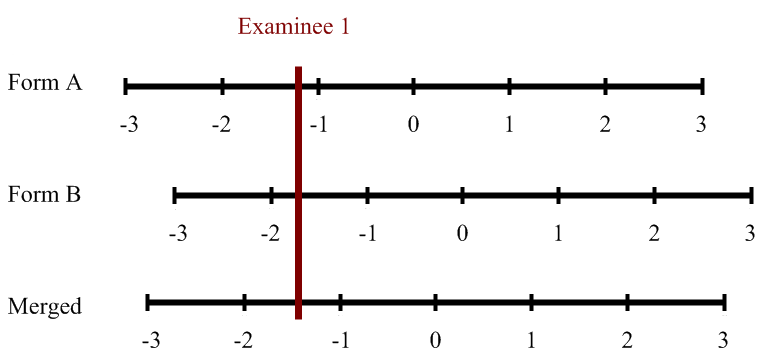
Concurrent Calibration
The second approach is to combine the datasets into what is known as a sparse matrix. You then run this single data set through the IRT calibration, and it will place all items and examinees onto a common scale. The concept of a sparse matrix is typically represented by the figure below, representing the non-equivalent anchor test (NEAT) design approach.
The IRT calibration software will automatically equate the two forms and you can use the resultant scores.
Fixed Anchor Calibration
The third approach is a combination of the two above; it utilizes the separate calibration concept but still uses the IRT calibration process to perform the equating rather than separate software.
With this approach, you would first calibrate your data for Form A. You then find all the IRT item parameters for the common items and input them into your IRT calibration software when you calibrate Form B.
You can tell the software to “fix” the item parameters so that those particular ones (from the common items) do not change. Then all the item parameters for the unique items are forced onto the scale of the common items, which of course is the underlying scale from Form A. This then also forces the scores from the Form B students onto the Form A scale.
How do these IRT equating approaches compare to each other?
Concurrent calibration is arguably the easiest but has the drawback that it merges the scales of each form into a new scale somewhere in the middle. If you need to report the scores on either form on the original scale, then you must use the Conversion or Fixed Anchor approaches. This situation commonly happens if you are equating across time periods.
Suppose you delivered Form A last year and are now trying to equate Form B. You can’t just create a new scale and thereby nullify all the scores you reported last year. You must map Form B onto Form A so that this year’s scores are reported on last year’s scale and everyone’s scores will be consistent.
Where do I go from here?
If you want to do IRT equating, you need IRT calibration software. All three approaches use it. I highly recommend Xcalibre since it is easy to use and automatically creates reports in Word for you. If you want to learn more about the topic of equating, the classic reference is the book by Kolen and Brennan (2004; 2014). There are other resources more readily available on the internet, like this free handbook from CCSSO. If you would like to learn more about IRT, I recommend the books by de Ayala (2008) and Embretson & Reise (2000). An intro is available in our blog post.
Education, to me, is the neverending opportunities we have for a cycle of instruction and assessment. This can be extremely small scale (watching a YouTube video on how to change a bike tire, then doing it) to large scale (teaching a 5th grad math curriculum and then assessing it nationwide). Psychometrics is the Science of Assessment – using scientific principles to make the assessment side of that equation more efficient, accurate, and defensible. How can psychometrics, especially its intersection with technology, improve assessment? Here are 10 important avenues to improve assessment with psychometrics.
10 ways to improve assessment with psychometrics
Job analysis
If you are doing assessment of anything job-related, from pre-employment screening tests of basic skills to a nationwide licensure exam for a high-profile profession, a job analysis is the essential first step. It uses a range of scientifically vetted and quantitatively leveraged approaches to help you define the scope of the exam.
Standard-setting studies
If a test has a cutscore, you need a defensible method to set that cutscore. Simply selecting a round number like 70% is asking for a disaster. There are a number of approaches from the scientific literature that will improve this process, including the Angoff method and Contrasting Groups method.
Automated Item generation
Newer assessment platforms will include functionality for automated item generation. There are two types: template-based and AI text generators.
Workflow management
Items are the basic building blocks of the assessment. If they are not high quality, everything else is a moot point. There needs to be formal processes in place to develop and review test questions. You should be using item banking software that helps you manage this process.
Linking
Linking and equating refer to the process of statistically determining comparable scores on different forms of an exam, including tracking a scale across years and completely different set of items. If you have multiple test forms or track performance across time, you need this. And IRT provides far superior methodologies.
Automated test assembly
The assembly of test forms – selecting items to match blueprints – can be incredibly laborious. That’s why we have algorithms to do it for you. Check out TestAssembler.
Item/Distractor analysis
If you are using items with selected responses (including multiple choice, multiple response, and Likert), a distractor/option analysis is essential to determine if those basic building blocks are indeed up to snuff. Our reporting platform in FastTest, as well as software like Itemanand Xcalibre, is designed for this purpose.
Item response theory (IRT)
This is the modern paradigm for developing large-scale assessments. Most important exams in the world over the past 40 years have used it, across all areas of assessment: licensure, certification, K12 education, postsecondary education, language, medicine, psychology, pre-employment… the trend is clear. For good reason. It will improve assessment.
Automated essay scoring
This technology is has become more widely available to improve assessment. If your organization scores large volumes of essays, you should probably consider this. Learn more about it here. There was a Kaggle competition on it in the past.
Computerized adaptive testing (CAT)
Tests should be smart. CAT makes them so. Why waste vast amounts of examinee time on items that don’t contribute to a reliable score, and just discourage the examinees? There are many other advantages too.