Multistage testing (MST) is a type of computerized adaptive testing (CAT). This means it is an exam delivered on computers which dynamically personalize it for each examinee or student. Typically, this is done with respect to the difficulty of the questions, by making the exam easier for lower-ability students and harder for high-ability students. Doing this makes the test shorter and more accurate while providing additional benefits. This post will provide more information on multistage testing so you can evaluate if it is a good fit for your organization.
Already interested in MST and want to implement it? Contact us to talk to one of our experts and get access to our powerful online assessment platform, where you can create your own MST and CAT exams in a matter of hours.
What is multistage testing?
Like CAT, multistage testing adapts the difficulty of the items presented to the student. But while adaptive testing works by adapting each item one by one using item response theory (IRT), multistage works in blocks of items. That is, CAT will deliver one item, score it, pick a new item, score it, pick a new item, etc. Multistage testing will deliver a block of items, such as 10, score them, then deliver another block of 10.
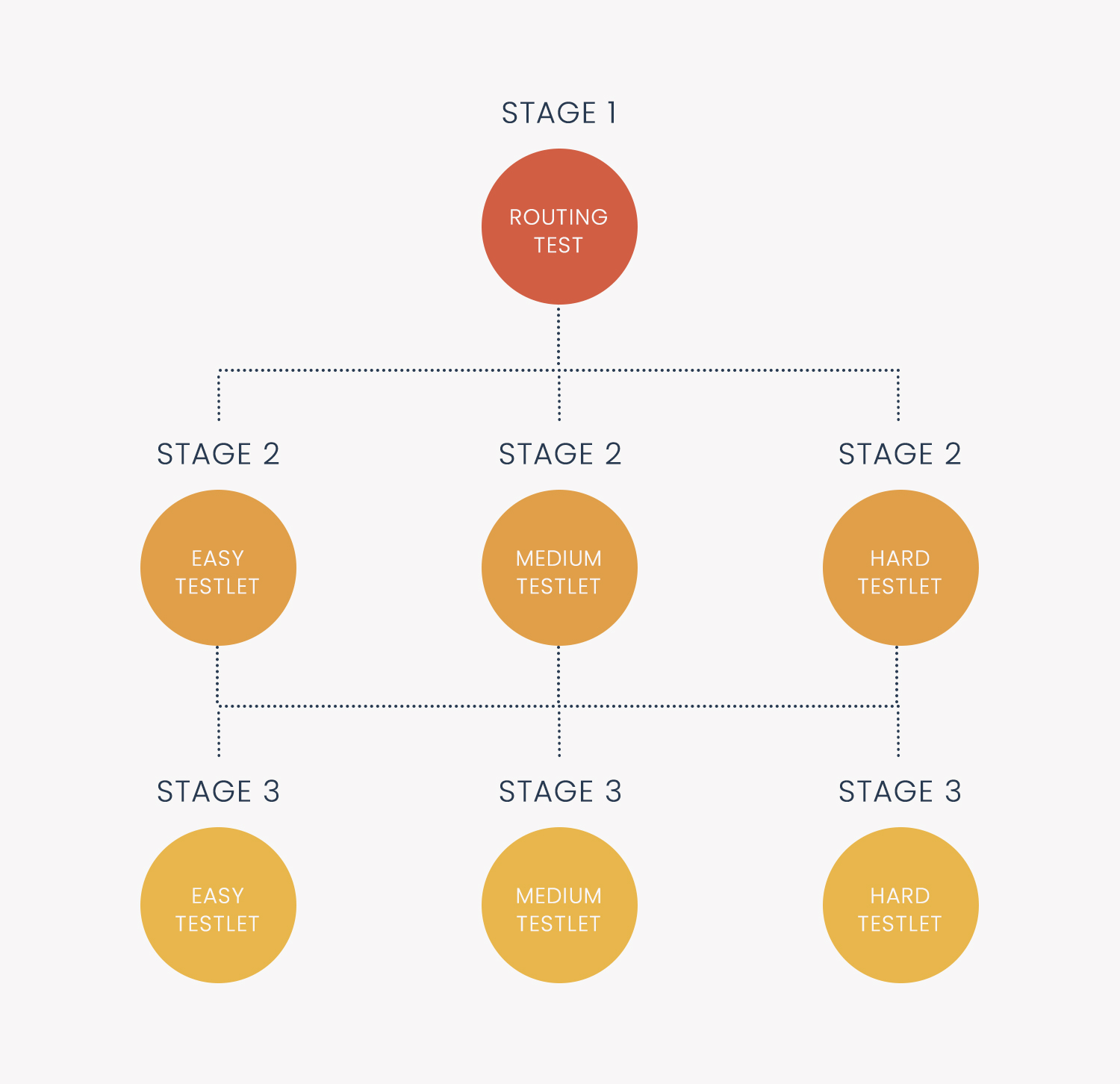
The design of a multistage test is often referred to as panels. There is usually a single routing test or routing stage which starts the exam, and then students are directed to different levels of panels for subsequent stages. The number of levels is sometimes used to describe the design; the example on the right is a 1-3-3 design. Unlike CAT, there are only a few potential paths, unless each stage has a pool of available testlets.
As with item-by-item CAT, multistage testing is almost always done using IRT as the psychometric paradigm, selection algorithm, and scoring method. This is because IRT can score examinees on a common scale regardless of which items they see, which is not possible using classical test theory.
Why multistage testing?
Item-by-item CAT is not the best fit for all assessments, especially those that naturally tend towards testlets, such as language assessments where there is a reading passage with 3-5 associated questions.
Multistage testing allows you to realize some of the well-known benefits of adaptive testing (see below), with more control over content and exposure. In addition to controlling content at an examinee level, it also can make it easier to manage item bank usage for the organization.
How do I implement multistage testing?
1. Develop your item banks using items calibrated with item response theory
2. Assemble a test with multiple stages, defining pools of items in each stage as testlets
3. Evaluate the test information functions for each testlet
4. Run simulation studies to validate the delivery algorithm with your predefined testlets
5. Publish for online delivery
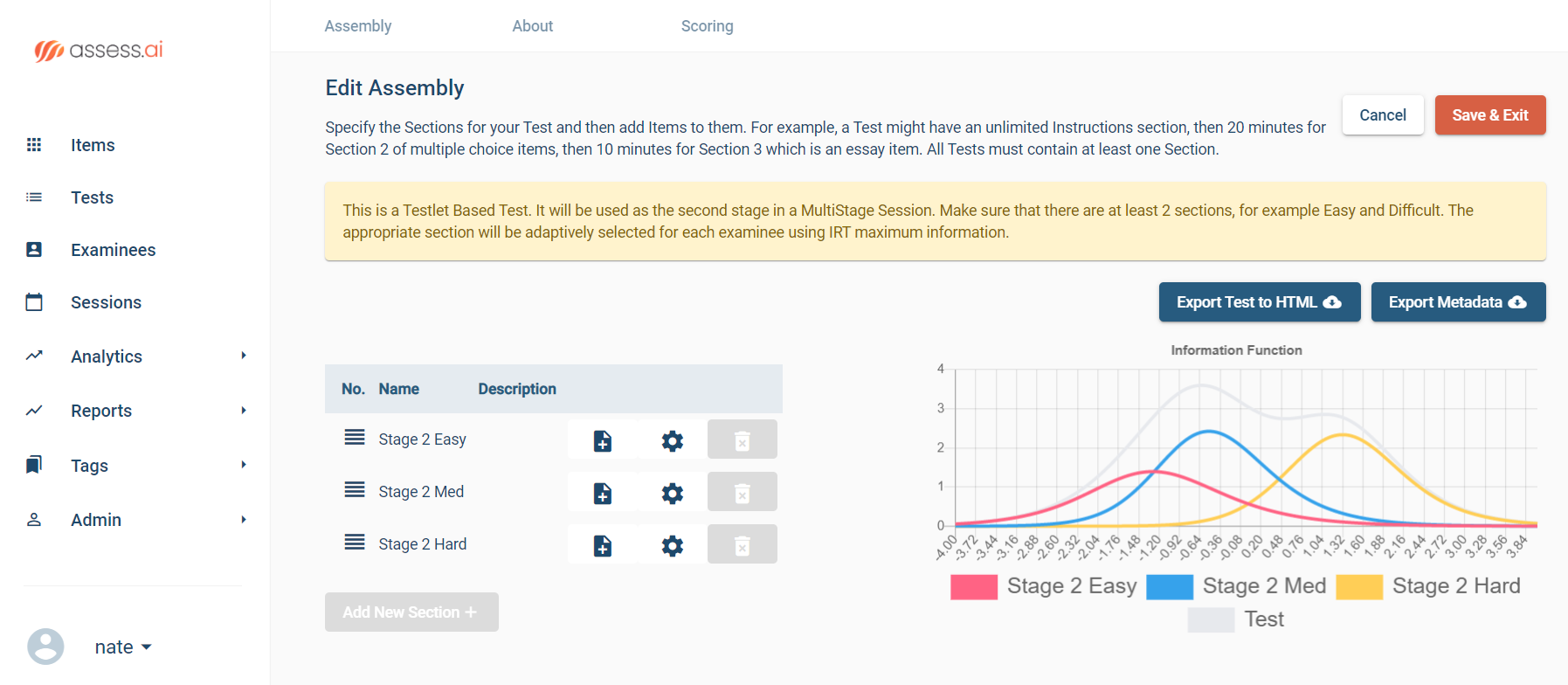
Our industry-leading assessment platform manages much of this process for you. The image to the right shows our test assembly screen where you can evaluate the test information functions for each testlet.
Benefits of MST
There are a number of benefits to this approach, which are mostly shared with CAT.
Shorter exams: because difficulty is targeted, you waste less time
Increased security: There are many possible configurations, unlike a linear exam where everyone sees the same set of items
Increased engagement: Lower ability students are not discouraged, and high ability students are not bored
Control of content: CAT has some content control algorithms, but they are sometimes not sufficient
Supports testlets: CAT does not support tests that have testlets, like a reading passage with 5 questions
Allows for review: CAT does not usually allow for review (students can go back a question to change an answer), while MST does
Examples of multistage testing
MST is often used in language assessment, which means that it is often used in educational assessment, such as benchmark K-12 exams, university admissions, or language placement/certification. One of the most famous examples is the Scholastic Aptitude Test from The College Board; it is moving to an MST approach in 2023.
Because of the complexity of item response theory, most organizations that implement MST have a full-time psychometrician on staff. If your organization does not, we would love to discuss how we can work together.
The College Board announced in January 2022 that it was planning to finally migrate the Scholastic Aptitude Test (SAT) from paper-and-pencil to computerized delivery. Moreover, it would make the tests “adaptive.” But what does it mean to have an adaptive SAT?
What is the SAT?
The SAT is the most commonly used exam for university admissions in the United States, though the ACT ranks a close second. Decades of research has shown that it accurately predicts important outcomes, such as 4-year graduation rates or GPA. Moreover, it provides incremental validity over other predictors, such as High School GPA. The adaptive SAT exam will use algorithms to make the test shorter, smarter, and more accurate.
Digital Assessment
Digital assessment, also known as electronic assessment or computer-based testing, refers to the delivery of exams via computers. It’s sometimes called online assessment or internet-based assessment as well, but not all software platforms are online, some stay secure on LANs.
What is “adaptive”?
When a test is adaptive, it means that it is being delivered with a computer algorithm that will adjust the difficulty of questions based on an individual’s performance. If you do well, you get tougher items. If you do not do well, you get easier items.
But while this seems straightforward and logical on the surface, there is a host of technical challenges to this. And, as researchers have delved into those challenges over the past 50 years, they have developed several approaches to how the adaptive algorithm can work.
Adapt the difficulty after every single item
Adapt the difficulty in blocks of items (sections), aka MultiStage Testing
Adapt the test in entirely different ways (e.g., decision trees based on machine learning models, or cognitive diagnostic models)
There are plenty of famous exams which use the first approach, including the NWEA MAP test and the Graduate Management Admissions Test (GMAT). But the SAT plans to use the second approach. There are several reasons to do so, an important one of which is that it allows you to use “testlets” which are items that are grouped together. For example, you probably remember test questions that have a reading passage with 3-5 attached questions; well, you can’t do that if you are picking a new standalone item after every item, as with Approach #1.
So how does it work? Each Adaptive SAT subtest will have two sections. An examinee will finish Section 1, and then based on their performance, get a Section 2 that is tailored to them. It’s not like it is just easy vs hard, either; there might be 30 possible Section 2s (10 each of Easy, Medium, Hard), or variations in between. A depiction of a 3-stage test is to the right.
How do we fairly score the results if students receive different questions? That issue has long been addressed by item response theory.
If you want to delve deeper into learning about adaptive algorithms, start over here.
Why an adaptive SAT?
The decades of research have shown adaptive testing to have well-known benefits. It requires fewer items to achieve the same level of accuracy in scores, which means shorter exams for everyone. It is also more secure, because not everyone sees the same items in the same order. It can produce a more engaging assessment as well, keeping the top performers challenged and avoid the lower performers checking out after getting too frustrated by difficult items. And, of course, using digital assessment has many advantages itself, such as faster score turnaround and enabling the use of tech-enhanced items. So, the migration to an adaptive SAT on top of being digital will be beneficial for the students.
https://assess.com/wp-content/uploads/2021/02/Multistage-testing-flow.jpg14521500Nathan Thompson, PhDhttps://assess.com/wp-content/uploads/2023/11/ASC-2022-Logo-no-tagline-300.pngNathan Thompson, PhD2022-03-15 05:24:502023-09-27 03:40:53The Adaptive SAT: what does that mean?
Paper-and-pencil testing used to be the only way to deliver assessments at scale. The introduction of computer-based testing (CBT) in the 1980s was a revelation – higher fidelity item types, immediate scoring & feedback, and scalability all changed with the advent of the personal computer and then later the internet. Delivery mechanisms including remote proctoringprovided students with the ability to take their exams anywhere in the world. This all exploded tenfold when the pandemic arrived. So why are some exams still offline, with paper and pencil?
Many education institutions are confused about which examination models to stick to. Should you go on with the online model they used when everyone was stuck in their homes? Should you adopt multi-modal examination models, or should you go back to the traditional pen-and-paper method?
This blog post will provide you with an evaluation of whether paper-and-pencil exams are still worth it in 2021.
Paper-and-pencil testing; The good, the bad, and the ugly
The Good
Offline exams have been a stepping stone towards the development of modern assessment models that are more effective. We can’t ignore the fact that there are several advantages of traditional exams.
Some advantages of paper-and-pencil testing include students having familiarity with the system, development of a social connection between learners, exemption from technical glitches, and affordability. Some schools don’t have the resources and pen-and-paper assessments are the only option available.
This is especially true in areas of the world that do not have the internet bandwidth or other technology necessary to deliver internet-based testing.
Another advantage of paper exams is that they can often work better for students with special needs, such as blind students which need a reader.
Paper and pencil testing is often more cost-efficient in certain situations where the organization does not have access to a professional assessment platform or learning management system.
The Bad and The Ugly
However, the paper-and-pencil testing does have a number of shortfalls.
1. Needs a lot of resources to scale
Delivery of paper-and-pencil testing at large scale requires a lot of resources. You are printing and shipping, sometimes with hundreds of trucks around the country. Then you need to get all the exams back, which is even more of a logistical lift.
2. Prone to cheating
Most people think that offline exams are cheat-proof but that is not the case. Most offline exams count on invigilators and supervisors to make sure that cheating does not occur. However, many pen-and-paper assessments are open to leakages. High candidate-to-ratio is another factor that contributes to cheating in offline exams.
3. Poor student engagement
We live in a world of instant gratification and that is the same when it comes to assessments. Unlike online exams which have options to keep the students engaged, offline exams are open to constant destruction from external factors.
Offline exams also have few options when it comes to question types.
4. Time to score
“To err is human.” But, when it comes to assessments, accuracy, and consistency. Traditional methods of hand-scoring paper tests are slow and labor-intensive. Instructors take a long time to evaluate tests. This defeats the entire purpose of assessments.
5. Poor result analysis
Pen-and-paper exams depend on instructors to analyze the results and come up with insight. This requires a lot of human resources and expensive software. It is also difficult to find out if your learning strategy is working or it needs some adjustments.
6. Time to release results
Online exams can be immediate. If you ship paper exams back to a single location, score them, perform psychometrics, then mail out paper result letters? Weeks.
7. Slow availability of results to analyze
Similarly, psychometricians and other stakeholders do not have immediate access to results. This prevents psychometric analysis, timely feedback to students/teachers, and other issues.
8. Accessibility
Online exams can be built with tools for zoom, color contrast changes, automated text-to-speech, and other things to support accessibility.
9. Convenience
Online tests are much more easily distributed. If you publish one on the cloud, it can immediately be taken, anywhere in the world.
10. Support for diversified question types
Unlike traditional exams which are limited to a certain number of question types, online exams offer many question types. Videos, audio, drag and drop, high-fidelity simulations, gamification, and much more are possible.
Sustainability is an important aspect of modern civilization. Online exams eliminate the need to use resources that are not environmentally friendly such as paper.
Conclusion
Is paper-and-pencil testing still useful? In most situations, it is not. The disadvantages outweigh the advantages. However, there are many situations where paper remains the only option, such as poor tech infrastructure.
Transitioning from paper-and-pencil testing to the cloud is not a simple task. That is why ASC is here to help you every step of the way, from test development to delivery. We provide you with the best assessment software and access to the most experienced team of psychometricians. Ready to take your assessments online?
Computerized adaptive testing (also computer-adaptive testing or adaptive assessment) is a modern assessment delivery method that uses AI algorithms to personalize the test to every examinee. This means that the test becomes shorter, more accurate, more secure, and fairer. The AI algorithms are almost always based on item response theory (IRT), an application of machine learning to assessment, but can be based on other models as well.
This post will cover the following topics:
What is computerized adaptive testing?
How does the test adapt?
An example of computerized adaptive testing
Advantages of computerized adaptive testing
How to develop an CAT that is valid and defensible
What do I need for adaptive testing?
Prefer to learn by doing? Request a free account in FastTest, our powerful adaptive testing platform.
Computerized adaptive testing: What is it?
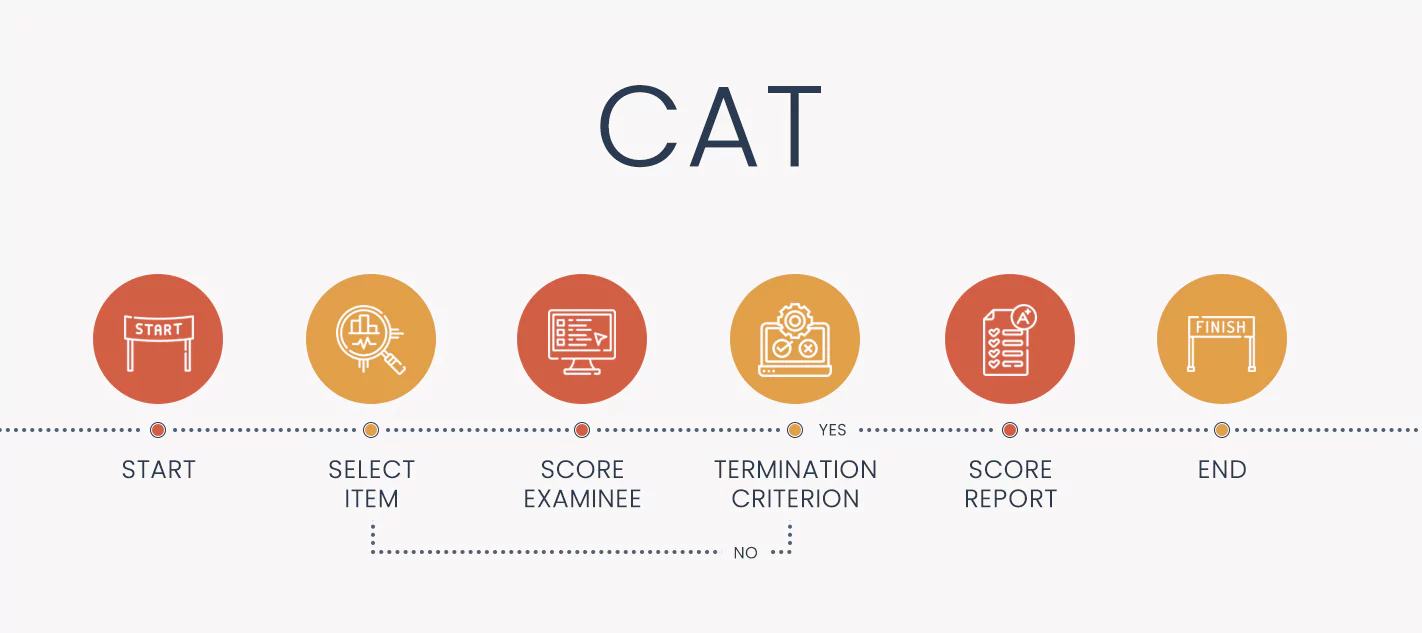
Computerized adaptive testing is an algorithm that personalizes how an assessment is delivered to each examinee. It is coded into a software platform, using the machine-learning approach of IRT to select items and score examinees. The algorithm proceeds in a loop until the test is complete. This makes the test smarter, shorter, fairer, and more precise.
The steps in the diagram above are adapted from Kingsbury and Weiss (1984). Let’s step through how it works.
For starters, you need an item bank that has been calibrated with a relevant psychometric or machine learning model. That is, you can’t just write a few items and subjectively rank them as Easy, Medium, or Hard difficulty. That’s an easy way to get sued. Instead, you need to write a large number of items (rule of thumb is 3x your intended test length) and then pilot them on a representative sample of examinees. The sample must be large enough to support the psychometric model you choose, and can range from 100 to 1000. You then need to perform simulation research – more on that later.
Once you have an item bank ready, here is how the computerized adaptive testing algorithm works for a student that sits down to take the test.
Starting point: there are three option to select the starting score, which psychometricians call theta
Everyone gets the same value, like 0.0 (average, in the case of non-Rasch models)
Randomized within a range, to help test security and item exposure
Predicted value, perhaps from external data, or from a previous exam
Select item
Find the item in the bank that has the highest information value
Often, you need to balance this with practical constraints such as Item Exposure or Content Balancing
Score examinee
Score the examinee; if using IRT, perhaps maximum likelihood or Bayes mod
32al
Evaluate termination criterion: using a predefined rule supported by your simulation research
Is a certain level of precision reached, such as a standard error of measurement <0.30
Are there no good items left in the bank
Has a time limit been reached
Has a Max Items limit been reached
The algorithm works by looping through 2-3-4 until the termination criterion is satisfied.
Adaptive testing software: Do I need to program all that myself?
No. Our revolutionary platform, FastTest, makes it easy to publish a CAT. Once you upload the IRT parameters, you can choose whatever options you please for steps 2-3-4 of the algorithm, simply by clicking on elements in our easy-to-use interface. Want to try it yourself? Contact us to set up a free account and demo.
But of course, there are many technical considerations that affect the quality and defensibility of your CAT – we’ll be talking about those in this post.
How does the test adapt? By Difficulty or Quantity?
CATs operate by adapting both the difficulty and quantity of items seen by each examinee.
Difficulty Most characterizations of computerized adaptive testing focus on how item difficulty is matched to examinee ability. High-ability examinees receive more difficult items, while low ability examinees receive easier items, which has important benefits to the student and the organization. An adaptive test typically begins by delivering an item of medium difficulty; if you get it correct, you get a tougher item, and if you get it incorrect, you get an easier item. This basic algorithm continues until the test is finished, though it usually includes sub algorithms for important things like content distribution and item exposure.
Quantity A less publicized facet of adaptation is the number of items. Adaptive tests can be designed to stop when certain psychometric criteria are reached, such as a specific level of score precision. Some examinees finish very quickly with few items, so that adaptive tests are typically about half as many questions as a regular test, with at least as much accuracy. Since some examinees have longer tests, these adaptive tests are referred to as variable-length. Obviously, this makes for a massive benefit: cutting testing time in half, on average, can substantially decrease testing costs.
Some adaptive tests use a fixed length, and only adapt item difficulty. This is merely for public relations issues, namely the inconvenience of dealing with examinees who feel they were unfairly treated by the CAT, even though it is arguably more fair and valid than conventional tests.
In general, it is best practice to meld the two: allow test length to be shorter or longer, but put caps on either end that prevent inadvertently too-short tests or tests that could potentially go on to 400 items. For example, the NCLEX has a minimum length exam of 75 items and the maximum length exam of 145 items.
An example of the computerized adaptive testing algorithm
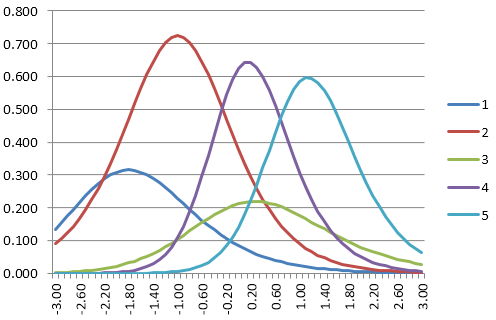
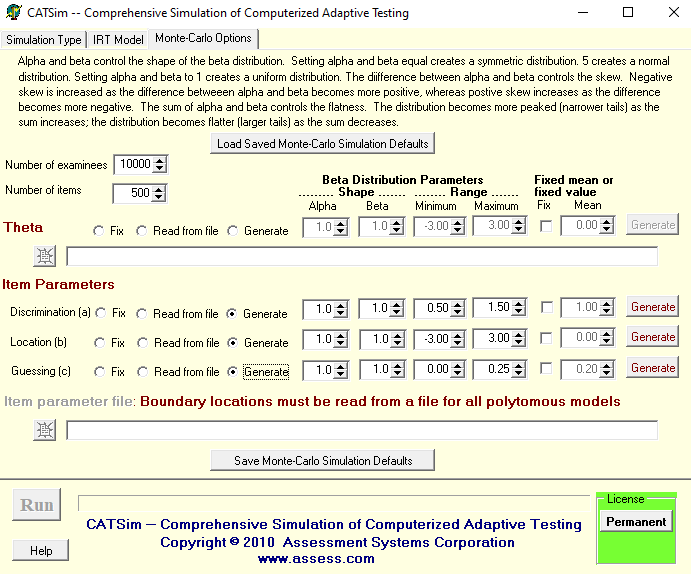
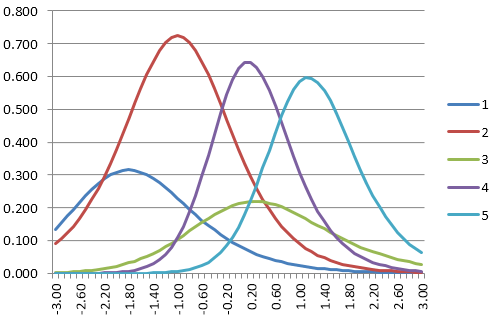
Let’s walk through an oversimplified example. Below are the item information functions for five items in a bank. Let’s suppose the starting theta is 0.0.
We find the first item to deliver. Which item has the highest information at 0.0? It is Item 4.
Suppose the student answers incorrectly.
We run the IRT scoring algorithm, and suppose the score is -2.0.
Check the termination criterion; we certainly aren’t done yet, after 1 item.
Find the next item. Which has the highest information at -2.0? Item 2.
Suppose the student answers correctly.
We run the IRT scoring algorithm, and suppose the score is -0.8.
Evaluate termination criterion; not done yet.
Find the next item. Item 2 is the highest at -0.8 but we already used it. Item 4 is next best, but we already used it. So the next best is Item 1.
Item 1 is very easy, so the student gets it correct.
New score is -0.2.
Best remaining item at -0.2 is Item 3.
Suppose the student gets it incorrect.
New score is perhaps -0.4.
Evaluate termination criterion. Suppose that the test has a max of 3 items, an extremely simple criterion. We have met it. The test is now done and automatically submitted.
Want to take an adaptive test yourself and see how it adapts? Here is a link to take an English Vocabulary test.
Advantages/benefits of computerized adaptive testing
By making the test more intelligent, adaptive testing provides a wide range of benefits. Some of the well-known advantages of adaptive testing, recognized by scholarly psychometric research, are listed below.
However, the development of an adaptive test is a very complex process that requires substantial expertise in item response theory (IRT) and CAT simulation research. Our experienced team of psychometricians can provide your organization with the requisite experience to implement adaptive testing and help your organization benefit from these advantages. Contact us to learn more.
Shorter tests
Research has found that adaptive tests produce anywhere from a 50% to 90% reduction in test length. This is no surprise. Suppose you have a pool of 100 items. A top student is practically guaranteed to get the easiest 70 correct; only the hardest 30 will make them think. Vice versa for a low student. Middle-ability students do no need the super-hard or the super-easy items.
Why does this matter? Primarily, it can greatly reduce costs. Suppose you are delivering 100,000 exams per year in testing centers, and you are paying $30/hour. If you can cut your exam from 2 hours to 1 hour, you just saved $3,000,000. Yes, there will be increased costs from the use of adaptive assessment, but you will likely save money in the end.
For the K12 assessment, you aren’t paying for seat time, but there is the opportunity cost of lost instruction time. If students are taking formative assessments 3 times per year to check on progress, and you can reduce each by 20 minutes, that is 1 hour; if there are 500,000 students in your State, then you just saved 500,000 hours of learning.
More precise scores
CAT will make tests more accurate, in general. It does this by designing the algorithms specifically around how to get more accurate scores without wasting examinee time.
More control of score precision (accuracy)
CAT ensures that all students will have the same accuracy, making the test much fairer. Traditional tests measure the middle students well but not the top or bottom students. Is it better than A) students see the same items but can have drastically different accuracy of scores, or B) have equivalent accuracy of scores, but see different items?
Better test security
Since all students are essentially getting an assessment that is tailored to them, there is better test security than everyone seeing the same 100 items. Item exposure is greatly reduced; note, however, that this introduces its own challenges, and adaptive assessment algorithms have considerations of their own item exposure.
A better experience for examinees, with reduced fatigue
Adaptive assessments will tend to be less frustrating for examinees on all ranges of ability. Moreover, by implementing variable-length stopping rules (e.g., once we know you are a top student, we don’t give you the 70 easy items), reduces fatigue.
Increased examinee motivation
Since examinees only see items relevant to them, this provides an appropriate challenge. Low-ability examinees will feel more comfortable and get many more items correct than with a linear test. High-ability students will get the difficult items that make them think.
Frequent retesting is possible
The whole “unique form” idea applies to the same student taking the same exam twice. Suppose you take the test in September, at the beginning of a school year, and take the same one again in November to check your learning. You’ve likely learned quite a bit and are higher on the ability range; you’ll get more difficult items, and therefore a new test. If it was a linear test, you might see the same exact test.
This is a major reason that adaptive assessment plays a formative role in K-12 education, delivered several times per year to millions of students in the US alone.
Individual pacing of tests
Examinees can move at their own speed. Some might move quickly and be done in only 30 items. Others might waver, also seeing 30 items but taking more time. Still, others might see 60 items. The algorithms can be designed to maximize the process.
Advantages of computerized testing in general
Of course, the advantages of using a computer to deliver a test are also relevant. Here are a few
Immediate score reporting
On-demand testing can reduce printing, scheduling, and other paper-based concerns
Storing results in a database immediately makes data management easier
Computerized testing facilitates the use of multimedia in items
You can immediately run psychometric reports
Timelines are reduced with an integrated item banking system
How to develop an CAT that is valid and defensible
CATs are the future of assessment. They operate by adapting both the difficulty and number of items to each individual examinee. The development of an adaptive test is no small feat, and requires five steps integrating the expertise of test content developers, software engineers, and psychometricians.
The development of a quality adaptive test is complex and requires experienced psychometricians in both item response theory (IRT) calibration and CAT simulation research. FastTest can provide you the psychometrician and software; if you provide test items and pilot data, we can help you quickly publish an adaptive version of your test.
Step 1: Feasibility, applicability, and planning studies. First, extensive monte carlo simulation research must occur, and the results formulated as business cases, to evaluate whether adaptive testing is feasible, applicable, or even possible.
Step 2: Develop item bank. An item bank must be developed to meet the specifications recommended by Step 1.
Step 3: Pretest and calibrate item bank. Items must be pilot tested on 200-1000 examinees (depends on IRT model) and analyzed by a Ph.D. psychometrician.
Step 4: Determine specifications for final CAT. Data from Step 3 is analyzed to evaluate CAT specifications and determine most efficient algorithms using CAT simulation software such as CATSim.
Step 5: Publish live CAT. The adaptive test is published in a testing engine capable of fully adaptive tests based on IRT. There are not very many of them out in the market. Sign up for a free account in our platform FastTest and try for yourself!
Here are some minimum requirements to evaluate if you are considering a move to the CAT approach.
A large item bank piloted so that each item has at least 100 valid responses (Rasch model) or 500 (3PL model)
500 examinees per year
Specialized IRT calibration and CAT simulation software like Xcalibre and CATsim.
Staff with a Ph.D. in psychometrics or an equivalent level of experience. Or, leverage our internationally recognized expertise in the field.
Items (questions) that can be scored objectively correct/incorrect in real-time
An item banking system and CAT delivery platform
Financial resources: Because it is so complex, the development of a CAT will cost at least $10,000 (USD) — but if you are testing large volumes of examinees, it will be a significantly positive investment. If you pay $20/hour for proctoring seats and cut a test from 2 hours to 1 hour for just 1,000 examinees… that’s a $20,000 savings. If you are doing 200,000 exams? That is $4,000,000 in seat time that is saved.
Adaptive testing: Resources for further reading
Visit the links below to learn more about adaptive testing.
ASC has been empowering organizations to develop better assessments since 1979. Curious as to how things were back then? Below is a copy of our newsletter from 1988, long before the days of sharing news via email and social media! Our platform at the time was named MICROCAT. This later became modernized to FastTest PC (Windows), then FastTest Web, and is now being reincarnated yet again as Assess.ai.
Special thanks to Cliff Donath for finding and sharing!
https://assess.com/wp-content/uploads/2019/02/CoCo3system.jpg8081166Nathan Thompson, PhDhttps://assess.com/wp-content/uploads/2023/11/ASC-2022-Logo-no-tagline-300.pngNathan Thompson, PhD2019-02-13 06:33:402019-02-13 06:33:40MICROCAT: What was assessment like in the 1980s?
Simulation studies are an essential step in the development of a computerized adaptive test (CAT) that is defensible and meets the needs of your organization or other stakeholders. There are three types of simulations: monte carlo, real data (post hoc), and hybrid.
Monte Carlo simulation is the most general-purpose approach, and the one most often used early in the process of developing a CAT. This is because it requires no actual data, either on test items or examinees – although real data is welcome if available – which makes it extremely useful in evaluating whether CAT is even feasible for your organization before any money is invested in moving forward.
Let’s begin with an overview of how Monte Carlo simulation works before we return to that point.
How a Monte Carlo Simulation works: An Overview
First of all, what do we mean by CAT simulation? Well, a CAT is a test that is administered to students via an algorithm. We can use that same algorithm on imaginary examinees, or real examinees from the past, and simulate how well a CAT performs on them.
Best of all, we can change the specifications of the algorithm to see how it impacts the examinees and the CAT performance.
Each simulation approach requires three things:
Item parameters from item response theory, though new CAT methods such as diagnostic models are now being developed
Examinee scores (theta) from item response theory
A way to determine how an examinee responds to an item if the CAT algorithm says it should be delivered to the examinee.
The monte Carlo simulation approach is defined by how it addresses the third requirement: it generates a response using some sort of mathematical model, while the other two simulation approaches look up actual responses for past examinees (real-data approach) or a mix of the two (hybrid).
The Monte Carlo simulation approach only uses the response generation process. The item parameters can either be from a bank of actual items or generated.
Likewise, the examinee thetas can be from a database of past data, or generated.
How does the response generation process work?
Well, it differs based on the model that is used as the basis for the CAT algorithm. Here, let’s assume that we are using the three-parameter logistic model. Start by supposing we have a fake examinee with a true theta of 0.0. The CAT algorithm looks in the bank and says that we need to administer item #17 as the first item, which has the following item parameters: a=1.0, b=0.0, and c=0.20.
Well, we can simply plug those numbers into the equation for the three-parameter model and obtain the probability that this person would correctly answer this item.
The probability, in this case, is 0.6. The next step is to generate a random number from the set of all real numbers between 0.0 and 1.0. If that number is less than the probability of correct response, the examinee “gets” the item correct. If greater, the examinee gets the item incorrect. Either way, the examinee is scored and the CAT algorithm proceeds.
For every item that comes up to be used, we utilize this same process. Of course, the true theta does not change, but the item parameters are different for each item. Each time, we generate a new random number and compare it to the probability to determine a response of correct or incorrect.
The CAT algorithm proceeds as if a real examinee is on the other side of the computer screen, actually responding to questions, and stops whenever the termination criterion is satisfied. However, the same process can be used to “deliver” linear exams to examinees; instead of the CAT algorithm selecting the next item, we just process sequentially through the test.
A road to research
For a single examinee, this process is not much more than a curiosity. Where it becomes useful is at a large scale aggregate level. Imagine the process above as part of a much larger loop. First, we establish a pool of 200 items pulled from items used in the past by your program. Next, we generate a set of 1,000 examinees by pulling numbers from a random distribution.
Finally, we loop through each examinee and administer a CAT by using the CAT algorithm and generating responses with the Monte Carlo simulation process. We then have extensive data on how the CAT algorithm performed, which can be used to evaluate the algorithm and the item bank. The two most important are the length of the CAT and its accuracy, which are a trade-off in most cases.
So how is this useful for evaluating the feasibility of CAT?
Well, you can evaluate the performance of the CAT algorithm by setting up an experiment to compare different conditions. Suppose you don’t have past items and are not even sure how many items you need? Well, you can create several different fake item banks and administer a CAT to the same set of fake examinees.
Or you might know the item bank to be used, but need to establish that a CAT will outperform the linear tests you currently use. There is a wide range of research questions you can ask, and since all the data is being generated, you can design a study to answer many of them. In fact, one of the greatest problems you might face is that you can get carried away and start creating too many conditions!
How do I actually do a Monte Carlo simulation study?
Fortunately, there is software to do all the work for you. The best option is CATSim, which provides all the options you need in a straightforward user interface (beware, this makes it even easier to get carried away). The advantage of CATSim is that it collates the results for you and presents most of the summary statistics you need without you having to calculate them. For example, it calculates the average test length (number of items used by a variable-length CAT), and the correlation of CAT thetas with true thetas. Other software exists which is useful in generating data sets using Monte Carlo simulation (see SimulCAT), but they do not include this important feature.
The traditional Learning Management System (LMS) is designed to serve as a portal between educators and their learners. Platforms like Moodle are successful in facilitating cooperative online learning in a number of groundbreaking ways: course management, interactive discussion boards, assignment submissions, and delivery of learning content. While all of this is great, we’ve yet to see an LMS that implements best practices in assessment and psychometrics to ensure that medium or high stakes tests meet international standards.
To put it bluntly, LMS systems have assessment functionality that is usually good enough for short classroom quizzes but falls far short of what is required for a test that is used to award a credential. A white paper on this topic is available here, but some examples include:
Treatment of items as reusable objects
Item metadata and historical use
Collaborative item review and versioning
Test assembly based on psychometrics
Psychometric forensics to search for non-independent test-taking behavior
Deeper score reporting and analytics
Assessment Systems is pleased to announce the launch of an easy-to-use bridge between FastTest and Moodle that will allow users to seamlessly deliver sound assessments from within Moodle while taking advantage of the sophisticated test development and psychometric tools available within FastTest. In addition to seamless delivery for learners, all candidate information is transferred to FastTest, eliminating the examinee import process. The bridge makes use of the international Learning Tools Interoperability standards.
If you are already a FastTest user, watch a step-by-step tutorial on how to establish the connection, in the FastTest User Manual by logging into your FastTest workspace and selecting Manual in the upper right-hand corner. You’ll find the guide in Appendix N.
If you are not yet a FastTest user and would like to discuss how it can improve your assessments while still allowing you to leverage Moodle or other LMS systems for learning content, sign up for a free account here.
Sympson-Hetter is a method of item exposure control within the algorithm of Computerized adaptive testing (CAT). It prevents the algorithm from over-using the best items in the pool.
CAT is a powerful paradigm for delivering tests that are smarter, faster, and fairer than the traditional linear approach. However, CAT is not without its challenges. One is that it is a greedy algorithm that always selects your best items from the pool if it can. The way that CAT researchers address this issue is with item exposure controls. These are sub algorithms that are injected into the main item selection algorithm, to alter it from always using the best items. The Sympson-Hetter method is one such approach. Another is the Randomesque method.
The Randomesque Method
The simplest approach is called the randomesque method. This selects from the top X items in terms of item information (a term from item response theory), usually for the first Y items in a test. For example, instead of always selecting the top item, the algorithm finds the 3 top items and then randomly selects between those.
The figure on the right displays item information functions (IIFs) for a pool of 5 items. Suppose an examinee had a theta estimate of 1.40. The 3 items with the highest information are the light blue, purple, and green lines (5, 4, 3). The algorithm would first identify this and randomly pick amongst those three. Without item exposure controls, it would always select Item 4.
The Sympson-Hetter Method
A more sophisticated method is the Sympson-Hetter method.
Here, the user specifies a target proportion as a parameter for the selection algorithm. For example, we might decide that we do not want an item seen by more than 75% of examinees. So, every time that the CAT algorithm goes into the item pool to select a new item, we generate a random number between 0 and 1, which is then compared to the threshold. If the number is between 0 and 0.75 in this case, we go ahead and administer the item. If the number is from 0.75 to 1.0, we skip over it and go on to the next most informative item in the pool, though we then do the same comparison for that item.
Why do this? It obviously limits the exposure of the item. But just how much it limits it depends on the difficulty of the item. A very difficult item is likely only going to be a candidate for selection for very high-ability examinees. Let’s say it’s the top 4%… well, then the approach above will limit it to 3% of the sample overall, but 75% of the examinees in its neighborhood.
On the other hand, an item of middle difficulty is used not only for middle examinees but often for any examinee. Remember, unless there are some controls, the first item for the test will be the same for everyone! So if we apply the Sympson-Hetter rule to that item, it limits it to 75% exposure in a more absolute sense.
Because of this, you don’t have to set that threshold parameter to the same value for each item. The original recommendation was to do some CAT simulation studies, then set the parameters thoughtfully for different items. Items that are likely to be highly exposed (middle difficulty with high discrimination) might deserve a more strict parameter like 0.40. On the other hand, that super-difficult item isn’t an exposure concern because only the top 4% of students see it anyway… so we might leave its parameter at 1.0 and therefore not limit it at all.
Is this the only method available?
No. As mentioned, there’s that simple randomesque approach. But there are plenty more. You might be interested in this paper, this paper, or this paper. The last one reviews the research literature from 1983 to 2005.
What is the original reference?
Sympson, J. B., & Hetter, R. D. (1985, October). Controlling item-exposure rates in computerized adaptive testing. Proceedings of the 27th annual meeting of the Military Testing Association (pp. 973–977). San Diego, CA: Navy Personnel Research and Development Center.
How can I apply this to my tests?
Well, you certainly need a CAT platform first. Our platform at ASC allows this method right out of the box – that is, all you need to do is enter the target proportion when you publish your exam, and the Sympson-Hetter method will be implemented. No need to write any code yourself! Click here to sign up for a free account.
In the past decade, terms like machine learning, artificial intelligence, and data mining are becoming greater buzzwords as computing power, APIs, and the massively increased availability of data enable new technologies like self-driving cars. However, we’ve been using methodologies like machine learning in psychometrics for decades. So much of the hype is just hype.
So, what exactly is Machine Learning?
Unfortunately, there is no widely agreed-upon definition, and as Wikipedia notes, machine learning is often conflated with data mining. A broad definition from Wikipedia is that machine learning explores the study and construction of algorithms that can learn from and make predictions on data. It’s often divided into supervised learning, where a researcher drives the process, and unsupervised learning, where the computer is allowed to creatively run wild and look for patterns. The latter isn’t of much use to us, at least yet.
Supervised learning includes specific topics like regression, dimensionality reduction, anomaly detection that we obviously have in Psychometrics. But its the general definition above that really fits what Psychometrics has been doing for decades.
What is Machine Learning in Psychometrics?
We can’t cover all the ways that machine learning and related topics are used in psychometrics and test development, but here’s a sampling. My goal is not to cover them all but to point out that this is old news and that should not get hung up on buzzwords and fads and marketing schticks – but by all means, we should continue to drive in this direction.
Dimensionality Reduction
One of the first, and most straightforward, areas is dimensionality reduction. Given a bunch of unstructured data, how can we find some sort of underlying structure, especially based on latent dimension? We’ve been doing this, utilizing methods like cluster analysis and factor analysis, since Spearman first started investigating the structure of intelligence 100 years ago. In fact, Spearman helped invent those approaches to solve the problems that he was trying to address in psychometrics, which was a new field at the time and had no methodology yet. How seminal was this work in psychometrics for the field of machine learning in general? The Coursera MOOC on Machine Learning uses Spearman’s work as an example in one of the early lectures!
Classification
Classification is a typical problem in machine learning. A common example is classifying images, and the classic dataset is the MNIST handwriting set (though Silicon Valley fans will think of the “not hot dog” algorithm). Given a bunch of input data (image files) and labels (what number is in the image), we develop an algorithm that most effectively can predict future image classification. A closer example to our world is the iris dataset, where several quantitative measurements are used to predict the species of a flower.
The contrasting groups method of setting a test cutscore is a simple example of classification in psychometrics. We have a training set where examinees are already classified as pass/fail by a criterion other than test score (which of course rarely happens, but that’s another story), and use mathematical models to find the cutscore that most efficiently divides them. Not all standard setting methods take a purely statistical approach; understandably, the cutscores cannot be decided by an arbitrary computer algorithm like support vector machines or they’d be subject to immediate litigation. Strong use of subject matter experts and integration of the content itself is typically necessary.
Of course, all tests that seek to assign examinees into categories like Pass/Fail are addressing the classification problem. Some of my earliest psychometric work on the sequential probability ratio test and the generalized likelihood ratio was in this area.
One of the best examples of supervised learning for classification, but much more advanced than the contrasting groups method, is automated essay scoring, which as been around for about 2 decades. It has all the classic trappings: a training set where the observations are classified by humans first, and then mathematical models are trained to best approximate the humans. What makes it more complex is that the predictor data is now long strings of text (student essays) rather than a single number.
Anomaly Detection
The most obvious way this is used in our field is psychometric forensics, trying to find examinees that are cheating or some other behavior that warrants attention. But we also use it to evaluate model fit, possibly removing items or examinees from our data set.
Using Algorithms to Learn/Predict from Data
Item response theory is a great example of the general definition. With IRT, we are certainly using a training set, which we call a calibration sample. We use it to train some models, which are then used to make decisions in future observations, primarily scoring examinees that take the test by predicting where those examinees would fall in the score distribution of the calibration sample. IRT is also applied to solve more sophisticated algorithmic problems: Computerized adaptive testing and automated test assembly are fantastic examples. We IRT more generally to learn from the data; which items are most effective, which are not, the ability range where the test provides most precision, etc.
What differs from the Classification problem is that we don’t have a “true state” of labels for our training set. That is, we don’t know what the true scores are of the examinees, or if they are truly a “pass” or a “fail” – especially because those terms can be somewhat arbitrary. It is for this reason we rely on a well-defined model with theoretical reasons for it fitting our data, rather than just letting a machine learning toolkit analyze it with any model it feels like.
Arguably, classical test theory also fits this definition. We have a very specific mathematical model that is used to learn from the data, including which items are stronger or more difficult than others, and how to construct test forms to be statistically equivalent. However, its use of prediction is much weaker. We do not predict where future examinees would fall in the distribution of our calibration set. The fact that it is test-form-specific hampers is generalizability.
Reinforcement learning
The Wikipedia article also mentions reinforcement learning. This is used less often in psychometrics because test forms are typically published with some sort of finality. That is, they might be used in the field for a year or two before being retired, and no data is analyzed in that time except perhaps some high level checks like the NCCA Annual Statistical Report. Online IRT calibration is a great example, but is rarely used in practice. There, response data is analyzed algorithmically over time, and used to estimate or update the IRT parameters. Evaluation of parameter drift also fits in this definition.
Use of Test Scores
We also use test scores “outside” the test in a machine learning approach. A classic example of this is using pre-employment test scores to predict job performance, especially with additional variables to increase the incremental validity. But I’m not going to delve into that topic here.
Automation
Another huge opportunity for machine learning in psychometrics that is highly related is automation. That is, programming computers to do tasks more effectively or efficient than humans. Automated test assembly and automated essay scoring are examples of this, but there are plenty of of ways that automation can help that are less “cool” but have more impact. My favorite is the creation of psychometrics reports; Iteman and Xcalibre do not produce any numbers also available in other software, but they automatically build you a draft report in MS Word, with all the tables, graphs, and narratives already embedded. Very unique. Without that automation, organizations would typically pay a PhD psychometrician to spend hours of time on copy-and-paste, which is an absolute shame. The goal of my mentor, Prof. David Weiss, and myself is to automate the test development cycle as a whole; driving job analysis, test design, item writing, item review, standard setting, form assembly, test publishing, test delivery, and scoring. There’s no reason people should be allowed to continue making bad tests, and then using those tests to ruin people’s lives, when we know so much about what makes a decent test.
Summary
I am sure there are other areas of psychometrics and the testing industry that are soon to be disrupted by technological innovations such as this. What’s next?
As this article notes, the future direction is about the systems being able to learn on their own rather than being programmed; that is, more towards unsupervised learning than supervised learning. I’m not sure how well that fits with psychometrics.
But back to my original point: psychometrics has been a data-driven field since its inception a century ago. In fact, we contributed some of the methodology that is used generally in the field of machine learning and data analytics. So it shouldn’t be any big news when you hear terms like machine learning, data mining, AI, or dimensionality reduction used in our field! In contrast, I think it’s more important to consider how we remove roadblocks to more widespread use.
One of the hurdles we need to overcome for machine learning in psychometrics yet is simply how to get more organizations doing what has been considered best practice for decades. There are two types of problem organizations. The first type is one that does not have the sample sizes or budget to deal with methodologies like I’ve discussed here. The salient example I always think of is a state licensure test required by law for a niche profession that might have only 3 examinees per year (I have talked with such programs!). Not much we can do there. The second type is those organizations that indeed have large sample sizes and a decent budget, but are still doing things the same way they did them 30 years ago. How can we bring modern methods and innovations to these organizations? Because they will definitely only make their tests more effective and fairer.
Item response theory (IRT) is a family of mathematical models in the field of psychometrics, which are used to design, analyze, and score exams. It is a very powerful psychometric paradigm that allows researchers to build stronger assessments. This post will provide an introduction to the theory, discuss benefits, and explain how item response theory is used.
IRT represents an important innovation in the field of psychometrics. While now 50 years old – assuming the “birth” is the classic Lord and Novick (1969) text – it is still underutilized and remains a mystery to many practitioners. So what is item response theory, and why was it invented? For starters, IRT is very complex and requires larger sample sizes, so it is not used in small-scale exams but most large-scale exams use it.
Item response theory is more than just a way of analyzing exam data, it is a paradigm to drive the entire lifecycle of designing, building, delivering, scoring, and analyzing assessments. It is much more complex than its predecessor, classical test theory, but is also far more powerful. IRT requires quite a bit of expertise, as well as specially-designed software. Click the link below to download our software Xcalibre, which provides a user-friendly and visual platform for implementing IRT.
The Driver: Problems with Classical Test Theory
Classical test theory (CTT) is approximately 100 years old, and still remains commonly used because it is appropriate for certain situations, and it is simple enough that it can be used by many people without formal training in psychometrics. Most statistics are limited to means, proportions, and correlations. However, its simplicity means that it lacks the sophistication to deal with a number of very important measurement problems. Here are just a few.
Sample dependency: Classical statistics are all sample dependent, and unusable on a different sample; results from IRT are sample-independent within a linear transformation (that is, two samples of different ability levels can be easily converted onto the same scale).
Test dependency: Classical statistics are tied to a specific test form, and do not deal well with sparse matrices introduced by multiple forms, linear on the fly testing, or adaptive testing.
Weak linking/equating: CTT has a number of methods for linking multiple forms, but they are weak compared to IRT.
Measuring the range of students: Classical tests are built for the average student, and do not measure high or low students very well; conversely, statistics for very difficult or easy items are suspect.
It is a family of mathematical models that try to describe how examinees respond to items (hence the name). These models can be used to evaluate item performance, because the description are quite useful in and of themselves. However, item response theory ended up doing so much more – namely, addressing the problems above.
IRT is model-driven, in that there is a specific mathematical equation that is assumed. There are different parameters that shape this equation to different needs. That’s what defines different IRT models.
IRT used to be known as latent trait theory and item characteristic curve theory.
Introduction to Item Response Theory: The Item Parameters
The foundation of IRT is a mathematical model defined by item parameters. For dichotomous items (those scored correct/incorrect), each item has three parameters:
a: the discrimination parameter, an index of how well the item differentiates low from top examinees; typically ranges from 0 to 2, where higher is better, though not many items are above 1.0.
b: the difficulty parameter, an index of what level of examinees for which the item is appropriate; typically ranges from -3 to +3, with 0 being an average examinee level.
c: the pseudo-guessing parameter, which is a lower asymptote; typically is focused on 1/k where k is the number of options.
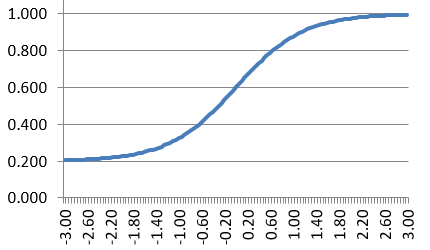
These parameters are used to graphically display an item response function (IRF), which models the probability of a correct answer as a function of ability. An example IRF is below. Here, the a parameter is approximately, 1.0, indicating a fairly discriminating test item. The b parameter is approximately 0.0 (the point on the x-axis where the midpoint of the curve is), indicating an average-difficulty item; examinees of average ability would have a 60% chance of answering correctly. The c parameter is approximately 0.20, like a 5-option multiple choice item.
What does this mean conceptually? We are trying to model the interaction of an examinee responding to an item, hence the name item response theory. Consider the x-axis to be z-scores on a standard normal scale. Examinees with higher ability are much more likely to respond correctly. Someone at +2.0 (97th percentile) has about a 94% chance of getting the item correct. Meanwhile, someone at -2.0 has only a 37% chance.
Of course, the parameters can and should differ from item to item, reflecting differences in item performance. The following graph shows five IRFs. The dark blue line is the easiest item, with a b of -2.00. The light blue item is the hardest, with a b of +1.80. The purple one has a c=0.00 while the light blue has c=0.25, indicating that it is susceptible to guessing.
These IRFs are not just a pretty graph or a way to describe how an item performs. They are the basic building block to accomplishing those important goals mentioned earlier. That comes next…
Applications of IRT to Improve Assessment
Item response theory uses the IRF for several purposes. Here are a few.
Interpreting and improving item performance
Scoring examinees with maximum likelihood or Bayesian methods
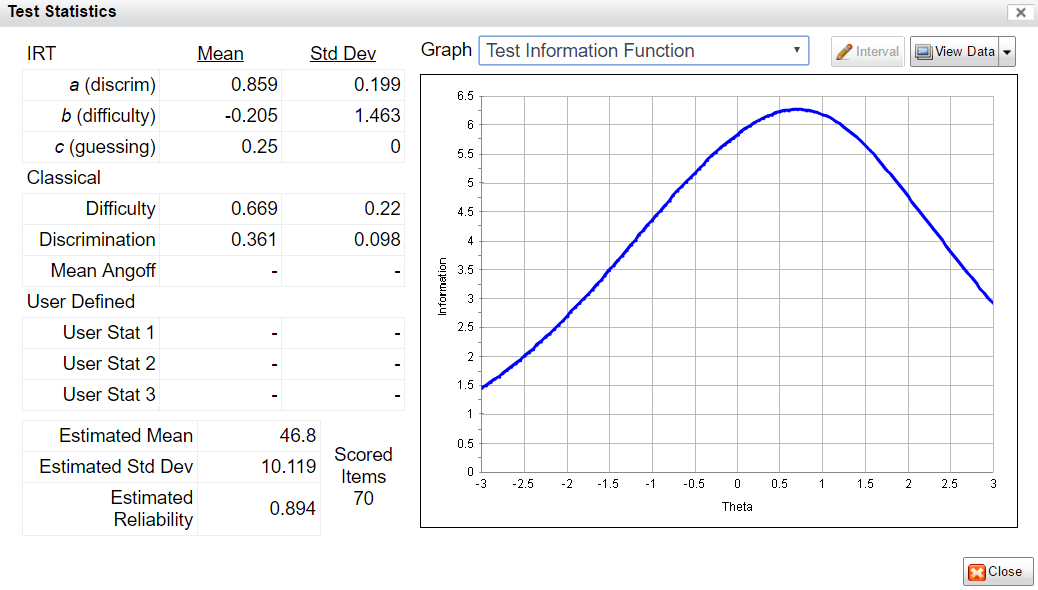
In addition to being used to evaluate each item individually, IRFs are combined in various ways to evaluate the overall test or form. The two most important approaches are the conditional standard error of measurement (CSEM) and the test information function (TIF). The test information function is higher where the test is providing more measurement information about examinees; if relatively low in a certain range of examinee ability, those examinees are not being measured accurately. The CSEM is the inverse of the TIF, and has the interpretable advantage of being usable for confidence intervals; a person’s score plus or minus 1.96 times the SEM is a 95% confidence interval for their score. The graph on the right shows part of the form assembly process in our FastTest platform.
Advantages and Benefits of Item Response Theory
So why does this matter? Let’s go back to the problems with classical test theory. Why is IRT better?
Sample-independence of scale: Classical statistics are all sample dependent, and unusable on a different sample; results from IRT are sample-independent. within a linear transformation. Two samples of different ability levels can be easily converted onto the same scale.
Test statistics: Classical statistics are tied to a specific test form.
Sparse matrices are OK: Classical test statistics do not work with sparse matrices introduced by multiple forms, linear on the fly testing, or adaptive testing.
Linking/equating: Item response theory has much stronger equating, so if your exam has multiple forms, or if you deliver twice per year with a new form, you can have much greater validity in the comparability of scores.
Measuring the range of students: Classical tests are built for the average student, and do not measure high or low students very well; conversely, statistics for very difficult or easy items are suspect.
Lack of accounting for guessing: CTT does not account for guessing on multiple choice exams.
Scoring: Scoring in classical test theory does not take into account item difficulty. With IRT, you can score a student on any set of items and be sure it is on the same latent scale.
Adaptive testing: CTT does not support adaptive testing in most cases. Adaptive testing has its own list of benefits.
Characterization of error: CTT assumes that every examinee has the same amount of error in their score (SEM); IRT recognizes that if the test is all middle-difficulty items, then low or high students will have inaccurate scores.
Stronger form building: IRT has functionality to build forms to be more strongly equivalent and meet the purposes of the exam.
Nonlinear function: IRT does not assume linear function of the student-item relationship when it is impossible. CTT assumes a linear function (point-biserial) when it is blatantly impossible.
One Big Happy Family
Remember: Item response theory is actually a family of models, making flexible use of the parameters. In some cases, only two (a,b) or one parameters (b) are used, depending on the type of assessment and fit of the data. If there are multipoint items, such as Likert rating scales or partial credit items, the models are extended to include additional parameters. Learn more about the partial credit situation here.
Here’s a quick breakdown of the family tree, with the most common models.
For more information, we recommend the textbook Item Response Theory for Psychologists by Embretson & Riese (2000) for those interested in a less mathematical treatment, or de Ayala (2009) for a more mathematical treatment. If you really want to dive in, you can try the 3-volume Handbook of Item Response Theory edited by van der Linden, which contains a chapter discussing ASC’s IRT analysis software, Xcalibre.
Want to talk to one of our experts about how to apply IRT? Get in touch!