Progress monitoring is an essential component of a modern educational system. Are you interested in tracking learners’ academic achievements during a period of learning, such as a school year? Then you need to design a valid and reliable progress monitoring system that would enable educators assist students in achieving a performance target. Progress monitoring is a standardized process of assessing a specific construct or a skill that should take place often enough to make pedagogical decisions and take appropriate actions.
Why Progress monitoring?
Progress monitoring mainly serves two purposes: to identify students in need and to adjust instructions based on assessment results. Such adjustments can be used on both individual and aggregate levels of learning. Educators should use progress monitoring data to make decisions about whether appropriate interventions should be employed to ensure that students obtain support to propel their learning and match their needs (Issayeva, 2017).
This assessment is usually criterion-referenced and not normed. Data collected after administration can show a discrepancy between students’ performances in relation to the expected outcomes, and can be graphed to display a change in rate of progress over time.
Progress monitoring dates back to the 1970s when Deno and his colleagues at the University of Minnesota initiated research on applying this type of assessment to observe student progress and identify the effectiveness of instructional interventions (Deno, 1985, 1986; Foegen et al., 2008). Positive research results suggested to use progress monitoring as a potential solution of the educational assessment issues existing in the late 1980s–early 1990s (Will, 1986).
Approaches to development of measures
Two approaches to item development are highly applicable these days: robust indicators and curriculum sampling (Fuchs, 2004). It is interesting to note, that advantages of using one approach tend to mirror disadvantages of the other one.
According to Foegen et al. (2008), robust indicators represent core competencies integrating a variety of concepts and skills. Classic examples of robust indicator measures are oral reading fluency in reading and estimation in Mathematics. The most popular illustration of this case is the Programme for International Student Assessment (PISA) that evaluates preparedness of students worldwide to apply obtained knowledge and skills in practice regardless of the curriculum they study at schools (OECD, 2012).
When using the second approach, a curriculum is analyzed and sampled in order to construct measures based on its proportional representations. Due to the direct link to the instructional curriculum, this approach enables teachers to evaluate student learning outcomes, consider instructional changes, and determine eligibility for other educational services. Progress monitoring is especially applicable when curriculum is spiral (Bruner, 2009) since it allows students revisit the same topics with increasing complexity.
CBM and CAT
Curriculum-based measures (CBMs) are commonly used for progress monitoring purposes. They typically embrace standardized procedures for item development, administration, scoring, and reporting. CBMs are usually conducted under timed conditions as this allows obtain evidence of a student’s fluency within a targeted skill.
Computerized adaptive tests (CATs) are gaining more and more popularity these days, particularly within progress monitoring framework. CATs were primarily developed to replace traditional fixed-length paper-and-pencil tests and have been proven to become a helpful tool determining each learner’s achievement levels (Weiss & Kingsbury, 1984).
CATs utilize item response theory (IRT) and provide students with subsequent items based on difficulty level and their answers in real time. In brief, IRT is a statistical method that parameterizes items and examinees on the same scale, and facilitates stronger psychometric approaches such as CAT (Weiss, 2004). Thompson and Weiss (2011) suggest a step-by-step guidance on how to build CATs.
Progress monitoring vs. traditional assessments
Progress monitoring significantly differs from traditional classroom assessments by many reasons. First, it provides objective, reliable, and valid data on student performance, e. g. in terms of the mastery of a curriculum. Subjective judgement is unavoidable for teachers when they prepare classroom assessments for their students. On the contrary, student progress monitoring measures and procedures are standardized which guarantees relative objectivity, as well as reliability and validity of assessment results (Deno, 1985; Foegen & Morrison, 2010). In addition, progress monitoring results are not graded, and there is no preparation prior to the test. Second, it leads to thorough feedback from teachers to students. Competent feedback helps teachers adapt their teaching methods or instructions in response to their students’ needs (Fuchs & Fuchs, 2011). Third, progress monitoring enables teachers help students in achieving long-term curriculum goals by tracking their progress in learning (Deno et al., 2001; Stecker et al., 2005). According to Hintze, Christ, and Methe (2005), progress monitoring data assist teachers in identifying specific actions towards instructional changes in order to help students in mastering all learning objectives from the curriculum. Ultimately, this results in a more effective preparation of students for the final high-stakes exams.
References
Bruner, J. S. (2009). The process of education. Harvard University Press.
Deno, S. L. (1985). Curriculum-based measurement: The emerging alternative. Exceptional children, 52, 219-232.
Deno, S. L. (1986). Formative evaluation of individual student programs: A new role of school psychologists. School Psychology Review, 15, 358-374.
Deno, S. L., Fuchs, L. S., Marston, D., & Shin, J. (2001). Using curriculum-based measurement to establish growth standards for students with learning disabilities. School Psychology Review, 30(4), 507-524.
Foegen, A., & Morrison, C. (2010). Putting algebra progress monitoring into practice: Insights from the field. Intervention in School and Clinic, 46(2), 95-103.
Foegen, A., Olson, J. R., & Impecoven-Lind, L. (2008). Developing progress monitoring measures for secondary mathematics: An illustration in algebra. Assessment for Effective Intervention, 33(4), 240-249.
Fuchs, L. S. (2004). The past, present, and future of curriculum-based measurement research. School Psychology Review, 33, 188-192.
Fuchs, L. S., & Fuchs, D. (2011). Using CBM for Progress Monitoring in Reading. National Center on Student Progress Monitoring.
Hintze, J. M., Christ, T. J., & Methe, S. A. (2005). Curriculum-based assessment. Psychology in the School, 43, 45–56. doi: 10.1002/pits.20128
Issayeva, L. B. (2017). A qualitative study of understanding and using student performance monitoring reports by NIS Mathematics teachers [Unpublished master’s thesis]. Nazarbayev University.
Samson, J. M. (2016). Human trafficking and globalization [Unpublished doctoral dissertation]. Virginia Polytechnic Institute and State University.
OECD (2012). Lessons from PISA for Japan, Strong Performers and Successful Reformers in Education. OECD Publishing.
Stecker, P. M., Fuchs, L. S., & Fuchs, D. (2005). Using curriculum-based measurement to improve student achievement: Review of research. Psychology in the Schools, 42(8), 795-819.
Thompson, N. A., & Weiss, D. A. (2011). A framework for the development of computerized adaptive tests. Practical Assessment, Research, and Evaluation, 16(1), 1.
Weiss, D. J., & Kingsbury, G. G. (1984). Application of computerized adaptive testing to educational problems. Journal of Educational Measurement, 21(4), 361-375.
Weiss, D. J. (2004). Computerized adaptive testing for effective and efficient measurement in counseling and education. Measurement and Evaluation in Counseling and Development, 37(2), 70-84.
Will, M. C. (1986). Educating children with learning problems: A shared responsibility. Exceptional children, 52(5), 411-415.
Vertical scaling is the process of placing scores from educational assessments measuring same/similar knowledge domains but at different ability levels onto a common scale (Tong & Kolen, 2008). The most common example is putting Mathematics and Language assessments for K-12 onto a single scale. While general information about scaling can be found at What is Scaling?, this article will focus specifically on vertical scaling.
Why vertical scaling?
A vertical scale is incredibly important, as enables inferences about student progress from one moment to another, e. g. from elementary to high school grades, and can be considered as a developmental continuum of student academic achievements. In other words, students move along that continuum as they develop new abilities, and their scale score alters as a result (Briggs, 2010).
This is not only important for individual students, because we can track learning and assign appropriate interventions or enrichments, but also in an aggregate sense. Which schools are growing more than others? Are certain teachers better? Perhaps there is a noted difference between instructional methods or curricula? Here, we are coming up to the fundamental purpose of assessment; just like it is necessary to have a bathroom scale to track your weight in a fitness regime, if a governments implements a new Math instructional method, how does it know that students are learning more effectively?
Using a vertical scale can create a common interpretive framework for test results across grades and, therefore, provide important data that inform individual and classroom instruction. To be valid and reliable, these data have to be gathered based on properly constructed vertical scales.
Vertical scales can be compared with rulers that measure student growth in some subject areas from one testing moment to another. Similarly to height or weight, student capabilities are assumed to grow with time. However, if you have a ruler that is only 1 meter long and you are trying to measure growth 3-year-olds to 10-year-olds, you would need to link two rulers together.
Construction of Vertical Scales
Construction of a vertical scale is a complicated process which involves making decisions on test design, scaling design, scaling methodology, and scale setup. Interpretation of progress on a vertical scale depends on the resulting combination of such scaling decisions (Harris, 2007; Briggs & Weeks, 2009). Once a vertical scale is established, it needs to be maintained over different forms and time. According to Hoskens et al. (2003), a method chosen for maintaining vertical scales affects the resulting scale, and, therefore, is very important.
A measurement model that is used to place student abilities on a vertical scale is represented by item response theory (IRT; Lord, 2012; De Ayala, 2009) or the Rasch model (Rasch, 1960). This approach allows direct comparisons of assessment results based on different item sets (Berger et al., 2019). Thus, each student is supposed to work with a selected bunch of items not similar to the items taken by other students, but still his results will be comparable with theirs, as well as with his own ones from other assessment moments.
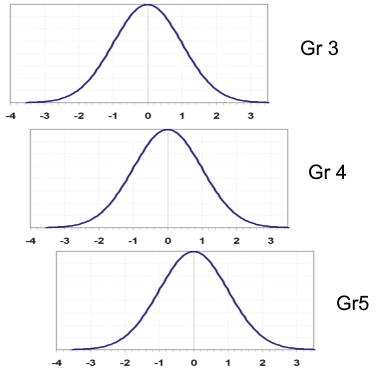
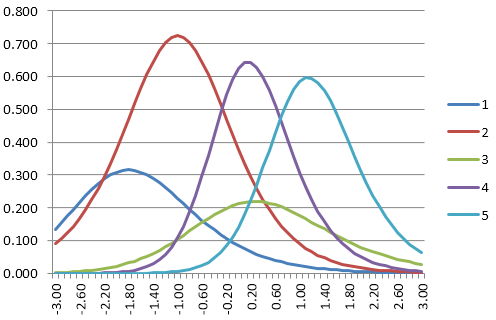
The image below shows how student results from different grades can be conceptualized by a common vertical scale. Suppose you were to calibrate data from each grade separately, but have anchor items between the three groups. A linking analysis might suggest that Grade 4 is 0.5 logits above Grade 3, and Grade 5 is 0.7 logits above Grade 4. You can think of the bell curves overlapped like you see below. A theta of 0.0 on the Grade 5 scale is equivalent to 0.7 on the Grade 4 scale, and 1.3 on the Grade 3 scale. If you have a strong linking, you can put Grade 3 and Grade 4 items/students onto the Grade 5 scale… as well as all other grades using the same approach.
Test design
Kolen and Brennan (2014) name three types of test designs aiming at collecting student response data that need to be calibrated:
Equivalent group design. Student groups with presumably comparable ability distributions within a grade are randomly assigned to answer items related to their own or an adjacent grade;
Common item design. Using identical items to students from adjacent grades (not requiring equivalent groups) to establish a link between two grades and to align overlapping item blocks within one grade, such as putting some Grade 5 items on the Grade 6 test, some Grade 6 items on the Grade 7 test, etc.;
Scaling test design. This type is very similar to common item design but, in this case, common items are shared not only between adjacent grades; there is a block of items administered to all involved grades besides items related to the specific grade.
From a theoretical perspective, the most consistent design with a domain definition of growth is scaling test design. Common item design is the easiest one to implement in practice but only if administering the same items to adjacent grades is reasonable from a content perspective. Equivalent group design requires more complicated administration procedures within one school grade to ensure samples with equivalent ability distributions.
Scaling design
The scaling procedure can use observed scores or it can be IRT-based. The most commonly used scaling design procedures in vertical scale settings are the Hieronymus, Thurstone, and IRT scaling (Yen, 1986; Yen & Burket, 1997; Tong & Harris, 2004). An interim scale is chosen in all these three methodologies (von Davier et al., 2006).
Hieronymus scaling. This method uses a total number-correct score for dichotomously scored tests or a total number of points for polytomously scored items (Petersen et al., 1989). The scaling test is constructed in a way to represent content in an increasing order in terms of level of testing, and it is administered to a representative sample from each testing level or grade. The within- and between-level variability and growth are set on an external scaling test, which is the special set of common items.
Thurstone scaling. According to Thurstone (1925, 1938), this method first creates an interim-score-scale and then normalizes distributions of variables at each level or grade. It assumes that scores on an underlying scale are normally distributed within each group of interest and, therefore, makes use of a total number-correct scores for dichotomously scored tests or a total number of points of polytomously scored items to conduct scaling. Thus, Thurstone scaling normalizes and linearly equates raw scores, and it is usually conducted within equivalent groups.
IRT scaling. This method of scaling considers person-item interactions. Theoretically, IRT scaling is applied for all existing IRT models, including multidimensional IRT models or diagnostic models. In practice, only unidimensional models, such as the Rasch and/or partial credit models (PCM) or the 3PL models, are used (von Davier et al., 2006).
Data calibration
When all decisions are taken, including test design and scaling design, and tests are administered to students, the items need to be calibrated with software like Xcalibre to establish a vertical measurement scale. According to Eggen and Verhelst (2011), item calibration within the context of the Rasch model implies the process of establishing model fit and estimating difficulty parameter of an item based on response data by means of maximum likelihood estimation procedures.
Two procedures, concurrent and grade-by-grade calibration, are employed to link IRT-based item difficulty parameters to a common vertical scale across multiple grades (Briggs & Weeks, 2009; Kolen & Brennan, 2014). Under concurrent calibration, all item parameters are estimated in a single run by means of linking items shared by several adjacent grades (Wingersky & Lord, 1983). In contrast, under grade-by-grade calibration, item parameters are estimated separately for each grade and then transformed into one common scale via linear methods. The most accurate method for determining linking constants by minimizing differences between linking items’ characteristic curves among grades is the Stocking and Lord method (Stocking & Lord, 1983). This is accomplished with software like IRTEQ.
Summary of Vertical Scaling
Vertical scaling is an extremely important topic in the world of educational assessment, especially K-12 education. As mentioned above, this is not only because it facilitates instruction for individual students, but is the basis for information on education at the aggregate level.
There are several approaches to implement vertical scaling, but the IRT-based approach is very compelling. A vertical IRT scale enables representation of student ability across multiple school grades and also item difficulty across a broad range of difficulty. Moreover, items and people are located on the same latent scale. Thanks to this feature, the IRT approach supports purposeful item selection and, therefore, algorithms for computerized adaptive testing (CAT). The latter use preliminary ability estimates for picking the most appropriate and informative items for each individual student (Wainer, 2000; van der Linden & Glas, 2010). Therefore, even if the pool of items is 1,000 questions stretching from kindergarten to Grade 12, you can deliver a single test to any student in the range and it will adapt to them. Even better, you can deliver the same test several times per year, and because students are learning, they will receive a different set of items. As such, CAT with a vertical scale is an incredibly fitting approach for K-12 formative assessment.
Additional Reading
Reckase (2010) states that the literature on vertical scaling is scarce going back to the 1920s, and recommends some contemporary practice-oriented research studies:
Paek and Young (2005). This research study dealt with the effects of Bayesian priors on the estimation of student locations on the continuum when using a fixed item parameter linking method. First, a within group calibration was done for one grade level; then the parameters from the common items in that calibration were fixed to calibrate the next grade level. This approach forces the parameter estimates to be the same for the common items at the adjacent grade levels. The study results showed that the prior distributions could affect the results and that careful checks should be done to minimize the effects.
Reckase and Li (2007). This book chapter depicts a simulation study of the dimensionality impacts on vertical scaling. Both multidimensional and unidimensional IRT models were employed to simulate data to observe growth across three achievement constructs. The results presented that the multidimensional model recovered the gains better than the unidimensional models, but those gains were underestimated mostly due to the common item selection. This emphasizes the importance of using common items that cover all of the content assessed at adjacent grade levels.
Li (2007). The goal of this doctoral dissertation was to identify if multidimensional IRT methods could be used for vertical scaling and what factors might affect the results. This study was based on a simulation designed to match state assessment data in Mathematics. The results showed that using multidimensional approaches was feasible, but it was important that the common items would include all the dimensions assessed at the adjacent grade levels.
Ito, Sykes, and Yao (2008). This study compared concurrent and separate grade group calibration while developing a vertical scale for nine consequent grades tracking student competencies in Reading and Mathematics. The research study used the BMIRT software implementing Markov-chain Monte Carlo estimation. The results showed that concurrent and separate grade group calibrations had provided different results for Mathematics than for Reading. This, in turn, confirms that the implementation of vertical scaling is very challenging, and combinations of decisions about its construction can have noticeable effects on the results.
Briggs and Weeks (2009). This research study was based on real data using item responses from the Colorado Student Assessment Program. The study compared vertical scales based on the 3PL model with those from the Rasch model. In general, the 3PL model provided vertical scales with greater rises in performance from year to year, but also greater increases within grade variability than the scale based on the Rasch model did. All methods resulted in growth curves having less gain along with an increase in grade level, whereas the standard deviations were not much different in size at different grade levels.
References
Berger, S., Verschoor, A. J., Eggen, T. J., & Moser, U. (2019, October). Development and validation of a vertical scale for formative assessment in mathematics. In Frontiers in Education (Vol. 4, p. 103). Frontiers. Retrieved from https://www.frontiersin.org/articles/10.3389/feduc.2019.00103/full
Briggs, D. C., & Weeks, J. P. (2009). The impact of vertical scaling decisions on growth interpretations. Educational Measurement: Issues and Practice, 28(4), 3–14.
Briggs, D. C. (2010). Do Vertical Scales Lead to Sensible Growth Interpretations? Evidence from the Field. Online Submission. Retrieved from https://files.eric.ed.gov/fulltext/ED509922.pdf
De Ayala, R. J. (2009). The Theory and Practice of Item Response Theory. New York: Guilford Publications Incorporated.
Eggen, T. J. H. M., & Verhelst, N. D. (2011). Item calibration in incomplete testing designs. Psicológica 32, 107–132.
Harris, D. J. (2007). Practical issues in vertical scaling. In Linking and aligning scores and scales (pp. 233–251). Springer, New York, NY.
Hoskens, M., Lewis, D. M., & Patz, R. J. (2003). Maintaining vertical scales using a common item design. In annual meeting of the National Council on Measurement in Education, Chicago, IL.
Ito, K., Sykes, R. C., & Yao, L. (2008). Concurrent and separate grade-groups linking procedures for vertical scaling. Applied Measurement in Education, 21(3), 187–206.
Kolen, M. J., & Brennan, R. L. (2014). Item response theory methods. In Test Equating, Scaling, and Linking (pp. 171–245). Springer, New York, NY.
Li, T. (2007). The effect of dimensionality on vertical scaling (Doctoral dissertation, Michigan State University. Department of Counseling, Educational Psychology and Special Education).
Lord, F. M. (2012). Applications of item response theory to practical testing problems. Routledge.
Paek, I., & Young, M. J. (2005). Investigation of student growth recovery in a fixed-item linking procedure with a fixed-person prior distribution for mixed-format test data. Applied Measurement in Education, 18(2), 199–215.
Petersen, N. S., Kolen, M. J., & Hoover, H. D. (1989). Scaling, norming, and equating. In R. L. Linn (Ed.), Educational measurement (3rd ed., pp. 221–262). New York: Macmillan.
Rasch, G. (1960). Probabilistic Models for Some Intelligence and Attainment Tests. Copenhagen: Danmarks Paedagogiske Institut.
Reckase, M. D., & Li, T. (2007). Estimating gain in achievement when content specifications change: a multidimensional item response theory approach. Assessing and modeling cognitive development in school. JAM Press, Maple Grove, MN.
Stocking, M. L., & Lord, F. M. (1983). Developing a common metric in item response theory. Applied psychological measurement, 7(2), 201–210. doi:10.1177/014662168300700208
Thurstone, L. L. (1925). A method of scaling psychological and educational tests. Journal of educational psychology, 16(7), 433–451.
Thurstone, L. L. (1938). Primary mental abilities (Psychometric monographs No. 1). Chicago: University of Chicago Press.
Tong, Y., & Harris, D. J. (2004, April). The impact of choice of linking and scales on vertical scaling. Paper presented at the annual meeting of the National Council on Measurement in Education, San Diego, CA.
Tong, Y., & Kolen, M. J. (2008). Maintenance of vertical scales. In annual meeting of the National Council on Measurement in Education, New York City.
van der Linden, W. J., & Glas, C. A. W. (eds.). (2010). Elements of Adaptive Testing. New York, NY: Springer.
von Davier, A. A., Carstensen, C. H., & von Davier, M. (2006). Linking competencies in educational settings and measuring growth. ETS Research Report Series, 2006(1), i–36. Retrieved from https://files.eric.ed.gov/fulltext/EJ1111406.pdf
Wainer, H. (Ed.). (2000). Computerized adaptive testing: A Primer, 2nd Edn. Mahwah, NJ: Lawrence Erlbaum Associates.
Wingersky, M. S., & Lord, F. M. (1983). An Investigation of Methods for Reducing Sampling Error in Certain IRT Procedures (ETS Research Reports Series No. RR-83-28-ONR). Princeton, NJ: Educational Testing Service.
Yen, W. M. (1986). The choice of scale for educational measurement: An IRT perspective. Journal of Educational Measurement, 23(4), 299–325.
Yen, W. M., & Burket, G. R. (1997). Comparison of item response theory and Thurstone methods of vertical scaling. Journal of Educational Measurement, 34(4), 293–313.
Test equating refers to the issue of defensibly translating scores from one test form to another. That is, if you have an exam where half of students see one set of items while the other half see a different set, how do you know that a score of 70 is the same one both forms? What if one is a bit easier? If you are delivering assessments in conventional linear forms – or piloting a bank for CAT/LOFT – you are likely to utilize more than one test form, and, therefore, are faced with the issue of test equating.
When two test forms have been properly equated, educators can validly interpret performance on one test form as having the same substantive meaning compared to the equated score of the other test form (Ryan & Brockmann, 2009). While the concept is simple, the methodology can be complex, and there is an entire area of psychometric research devoted to this topic. This post will provide an overview of the topic.
Why do we need test linking and equating?
The need is obvious: to adjust for differences in difficulty to ensure that all examinees receive a fair score on a stable scale. Suppose you take Form A and get a score of 72/100 while your friend takes Form B and gets a score of 74/100. Is your friend smarter than you, or did his form happen to have easier questions? What if the passing score on the exam was 73? Well, if the test designers built-in some overlap of items between the forms, we can answer this question empirically.
Suppose the two forms overlap by 50 items, called anchor items or equator items. They are delivered to a large, representative sample. Here are the results.
Mean score on 50 overlap items
Mean score on 100 total items
30
72
32
74
Because the mean score on the anchor items was higher, we then think that the Form B group was a little smarter, which led to a higher total score.
Now suppose these are the results:
Mean score on 50 overlap items
Mean score on 100 total items
32
72
32
74
Now, we have evidence that the groups are of equal ability. The higher total score on Form B must then be because the unique items on that form are a bit easier.
What is test equating?
According to Ryan and Brockmann (2009), “Equating is a technical procedure or process conducted to establish comparable scores, with equivalent meaning, on different versions of test forms of the same test; it allows them to be used interchangeably.” (p. 8). Thus, successful equating is an important factor in evaluating assessment validity, and, therefore, it often becomes an important topic of discussion within testing programs.
Practice has shown that scores, and tests producing scores, must satisfy very strong requirements to achieve this demanding goal of interchangeability. Equating would not be necessary if test forms were assembled as strictly parallel, meaning that they would have identical psychometric properties. In reality, it is almost impossible to construct multiple test forms that are strictly parallel, and equating is necessary to attune a test construction process.
Dorans, Moses, and Eignor (2010) suggest the following five requirements towards equating of two test forms:
tests should measure the same construct (e.g. latent trait, skill, ability);
tests should have the same level of reliability;
equating transformation for mapping the scores of tests should be the inverse function;
test results should not depend on the test form an examinee actually takes;
the equating function used to link the scores of two tests should be the same regardless of the choice of (sub) population from which it is derived.
How do I calculate an equating?
Classical test theory (CTT) methods include linear equating and equipercentile equating as well as several others. Some newer approaches that work well with small samples are Circle-Arc (Livingston & Kim, 2009) and Nominal Weights (Babcock, Albano, & Raymond, 2012). Specific methods for linear equating include Tucker, Levine, and Chained (von Davier & Kong, 2003). Linear equating approaches are conceptually simple and easy to interpret; given the examples above, the equating transformation might be estimated with a slope of 1.01 and an intercept of 1.97, which would directly confirm the hypothesis that one form was about 2 points easier than the other.
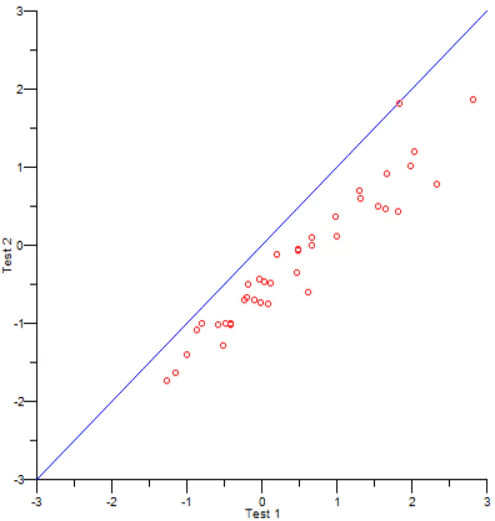
Item response theory (IRT) approaches include equating through common items (equating by applying an equating constant, equating by concurrent or simultaneous calibration, and equating with common items through test characteristic curves), and common person calibration (Ryan & Brockmann, 2009). The common-item approach is quite often used, and specific methods for finding the constants (conversion parameters) include Stocking-Lord, Haebara, Mean/Mean, and Mean/Sigma. Because IRT assumes that two scales on the same construct differ by only a simple linear transformation, all we need to do is find the slope and intercept of that transformation. Those methods do so, and often produce nice looking figures like the one below from the program IRTEQ (Han, 2007). Note that the b parameters do not fall on the identity line, because there was indeed a difference between the groups, and the results clearly find that is the case.
Practitioners can equate forms with CTT or IRT. However, one of the reasons that IRT was invented was that equating with CTT was very weak. Hambleton and Jones (1993) explain that when CTT equating methods are applied, both ability parameter (i.e., observed score) and item parameters (i.e., difficulty and discrimination) are dependent on each other, limiting its utility in practical test development. IRT solves the CTT interdependency problem by combining ability and item parameters in one model. The IRT equating methods are more accurate and stable than the CTT methods (Hambleton & Jones, 1993; Han, Kolen, & Pohlmann, 1997; De Ayala, 2013; Kolen and Brennan, 2014) and provide a solid basis for modern large-scale computer-based tests, such as computerized adaptive tests (Educational Testing Service, 2010; OECD, 2017).
Of course, one of the reasons that CTT is still around in general is that it works much better with smaller samples, and this is also the case for CTT test equating (Babcock, Albano, & Raymond, 2012).
How do I implement test equating?
Test equating is a mathematically complex process, regardless of which method you use. Therefore, it requires special software. Here are some programs to consider.
CIPE performs both linear and equipercentile equating with classical test theory. It is available from the University of Iowa’s CASMA site, which also includes several other software programs.
IRTEQ is an easy-to-use program which performs all major methods of IRT Conversion equating. It is available from the University of Massachusetts website, as well as several other good programs.
There are many R packages for equating and related psychometric topics. This article claims that there are 45 packages for IRT analysis alone!
If you want to do IRT equating, you need IRT calibration software. We highly recommend Xcalibre since it is easy to use and automatically creates reports in Word for you. If you want to do the calibration approach to IRT equating (both anchor-item and concurrent-calibration), rather than the conversion approach, this is handled directly by IRT software like Xcalibre. For the conversion approach, you need separate software like IRTEQ.
Equating is typically performed by highly trained psychometricians; in many cases, an organization will contract out to a testing company or consultant with the relevant experience. Contact us if you’d like to discuss this.
Does equating happen before or after delivery?
Both. These are called pre-equating and post-equating (Ryan & Brockmann, 2009). Post-equating means the calculation is done after delivery and you have a full data set, for example if a test is delivered twice per year on a single day, we can do it after that day. Pre-equating is more tricky, because you are trying to calculate the equating before a test form has ever been delivered to an examinee; but this is 100% necessary in many situations, especially those with continuous delivery windows.
How do I learn more about test equating?
If you are eager to learn more about the topic of equating, the classic reference is the book by Kolen and Brennan (2004; 2014) that provides the most complete coverage of score equating and linking. There are other resources more readily available on the internet, like this free handbook from CCSSO. If you would like to learn more about IRT, we suggest the books by De Ayala (2008) and Embretson and Reise (2000). A brief intro of IRT equating is available on our website.
Several new ideas of general use in equating, with a focus on kernel equating, were introduced in the book by von Davier, Holland, and Thayer (2004). Holland and Dorans (2006) presented a historical background for test score linking, based on work by Angoff (1971), Flanagan (1951), and Petersen, Kolen, and Hoover (1989). If you look for a straightforward description of the major issues and procedures encountered in practice, then you should turn to Livingston (2004).
Angoff, W. H. (1971). Scales, norms and equivalent scores. In R. L. Thorndike (Ed.), Educational measurement (2nd ed., pp. 508-600). American Council on Education.
Babcock, B., Albano, A., & Raymond, M. (2012). Nominal Weights Mean Equating: A Method for Very Small Samples. Educational and Psychological Measurement, 72(4), 1-21.
Dorans, N. J., Moses, T. P., & Eignor, D. R. (2010). Principles and practices of test score equating. ETS Research Report Series, 2010(2), i-41.
De Ayala, R. J. (2008). A commentary on historical perspectives on invariant measurement: Guttman, Rasch, and Mokken.
De Ayala, R. J. (2013). Factor analysis with categorical indicators: Item response theory. In Applied quantitative analysis in education and the social sciences (pp. 220-254). Routledge.
Educational Testing Service (2010). Linking TOEFL iBT Scores to IELTS Scores: A Research Report. Educational Testing Service.
Embretson, S. E., & Reise, S. P. (2000). Item response theory for psychologists. Maheah.
Flanagan, J. C. (1951). Units, scores, and norms. In E. F. Lindquist (Ed.), Educational measurement (pp. 695-763). American Council on Education.
Hambleton, R. K., & Jones, R. W. (1993). Comparison of classical test theory and item response theory and their applications to test development. Educational measurement: issues and practice, 12(3), 38-47.
Han, T., Kolen, M., & Pohlmann, J. (1997). A comparison among IRT true-and observed-score equatings and traditional equipercentile equating. Applied Measurement in Education, 10(2), 105-121.
Holland, P. W., & Dorans, N. J. (2006). Linking and equating. In R. L. Brennan (Ed.), Educational measurement (4th ed., pp. 187-220). Praeger.
Kolen, M. J., & Brennan, R. L. (2004). Test equating, linking, and scaling: Methods and practices (2nd ed.). Springer-Verlag.
Kolen, M. J., & Brennan, R. L. (2014). Item response theory methods. In Test Equating, Scaling, and Linking (pp. 171-245). Springer.
Livingston, S. A. (2004). Equating test scores (without IRT). ETS.
Livingston, S. A., & Kim, S. (2009). The Circle‐Arc Method for Equating in Small Samples. Journal of Educational Measurement 46(3): 330-343.
Petersen, N. S., Kolen, M. J., & Hoover, H. D. (1989). Scaling, norming and equating. In R. L. Linn (Ed.), Educational measurement (3rd ed., pp. 221-262). Macmillan.
Ryan, J., & Brockmann, F. (2009). A Practitioner’s Introduction to Equating with Primers on Classical Test Theory and Item Response Theory. Council of Chief State School Officers.
von Davier, A. A., Holland, P. W., & Thayer, D. T. (2004). The kernel method of test equating. Springer.
von Davier, A. A., & Kong, N. (2003). A unified approach to linear equating for non-equivalent groups design. Research report 03-31 from Educational Testing Service. https://www.ets.org/Media/Research/pdf/RR-03-31-vonDavier.pdf
Positive manifold refers to the fact that scores on cognitive assessment tend to correlate very highly with each other, indicating a common latent dimension that is very strong. This latent dimension became known as g for general intelligence or general cognitive ability. This post discusses what the positive manifold is, but since there are MANY other resources on the definition, the post also explains how this concept is useful in the real world.
The term positive manifold originally came out of work in the field of intelligence testing, including research by Charles Spearman. There literally hundreds of studies on this topic, and over one hundred years of research has shown that this concept is scientifically supported, but it is important to remember that it is just a manifold and not a perfect relationship. That is, we can expect verbal reasoning ability to correlate highly with quantitative reasoning or logical reasoning, but it is by no means a 1-to-1 relationship. There are certainly some people that can be high on one but not another. But it is very unlikely for you to be in the 90th percentile on one but 10th percentile on another.
What is Positive Manifold?
If you were to take a set of cognitive tests, either separate, or as subtests of a battery like the Wechsler Adult Intelligence Scale, and correlate their scores, the correlation matrix would be overwhelmingly positive. For example, look at Table 2-9 in this book. There are many, many more examples if you search for keywords like “intelligence intercorrelation.”
As you might expect, related constructs will correlate more highly. A battery might have a Verbal Reasoning test and a Vocabulary test; we would expect these to correlate more highly with each other (maybe 0.80) than a Figural Reasoning test (maybe 0.50). Researchers like to use a methodology called factor analysis to analyze this structure and drive interpretations.
Practical implications
Positive manifold and the structure of cognitive ability is historically an academic research topic, and remains so. Researchers are still publishing articles like this one. However, the concept of positive manifold has many practical implications in the real world. It affects situations where cognitive ability testing is used to obtain information about people and make decisions about them. Two of the most common examples are test batteries for admissions/placement or employment.
Admissions/placement exams are used in the education sector to evaluate student ability and make decisions about schools or courses that the student can/should enter. Admissions refers to whether the student should be admitted to a school, such as a university or a prestigious high school. Examples of this in the USA are the SAT and ACT exams. Placement refers to sending students to the right course, such as testing them on Math and English to determine if they are ready for certain courses. Both of these examples will typically test the student on 3 or 4 aspects, which is an example of a test battery. The SAT discusses intercorrelations of its subtests in the technical manual (page 104). Tests like the SAT can provide incremental validity above the predictive power of high school grade point average (HSGPA) alone, as seen in this report.
Employment testing is also often done with several cognitive tests. You might take psychometric tests to apply for a job, and they test you on quantitative reasoning and verbal reasoning.
In both cases, the tests are validated by doing research to show that they predict a criterion of interest. In the case of university admissions, this might be First Year GPA or Four Year Graduation Rate. In the case of Employment Testing, it could be Job Performance Rating by a supervisor or 1-year retention rate.
Why are they using multiple tests? They are trying to capitalize on the differences to get more predictive power for the criterion. Success in university isn’t due to just verbal/language skills alone, but also logical reasoning and other skills. They recognize that there is a high correlation, but the differences between the constructs can be leveraged to get more information about people. Employment testing goes further, and tries to add incremental validity by adding other tests that are completely unrelated but relevant to the job world, like job samples or even noncognitive tests like Conscientiousness . These also correlate with job performance, and therefore help with prediction, but correlate even lower with measures of g than another cognitive test would; this then adds more prediction power.
The Bookmark Method of standard setting (Lewis, Mitzel, & Green, 1996) is a scientifically-based approach to setting cutscores on an examination. It allows stakeholders of an assessment to make decisions and classifications about examinees that are constructive rather than arbitrary (e.g., 70%), meet the goals of the test, and contribute to overall validity. A major advantage of the bookmark method over others is that it utilizes difficulty statistics on all items, making it very data-driven; but this can also be a disadvantage in situations where such data is not available. It also has the advantage of panelist confidence (Karantonis & Sireci, 2006).
The bookmark method operates by delivering a test to a representative sample (or population) of examinees, and then calculating the difficulty statistics for each item. We line up the items in order of difficulty, and experts review the items to place a bookmark where they think a cutscore should be. Nowadays, we use computer screens, but of course in the past this was often done by printing the items in paper booklets, and the experts would literally insert a bookmark.
What is standard setting?
Standard setting (Cizek & Bunch, 2006) is an integral part of the test development process even though it has been undervalued outside of practitioners’ view in the past (Bejar, 2008). Standard setting is the methodology of defining achievement or proficiency levels and corresponding cutscores. A cutscore is a score that serves as a measure of classifying test takers into categories.
Educational assessments and credentialing examinations are often employed to distribute test takers among ordered categories according to their performance across specific content and skills (AERA, APA, & NCME, 2014; Hambleton, 2013). For instance, in tests used for certification and licensing purposes, test takers are typically classified as “pass”—those who score at or above the cutscore—and those who “fail”. In education, students are often classified in terms of proficiency; the Nation’s Report Card assessment (NAEP) in the United States classifies students as Below Basic, Basic, Proficient, Advanced.
However, assessment results could come into question unless the cutscores are appropriately defined. This is why arbitrary cutscores are considered indefensible and lacking validity. Instead, psychometricians help test sponsors to set cutscores using methodologies from the scientific literature, driven by evaluations of item and test difficulty as well as examinee performance.
When to use the bookmark method?
Two approaches are mainly used in international practice to establish assessment standards: the Angoff method (Cizek, 2006) and the Bookmark method (Buckendahl, Smith, Impara, & Plake, 2000). The Bookmark method, unlike the Angoff method, requires the test to be administered prior to defining cutscores based on test data. This provides additional weight to the validity of the process, and better informs the subject matter experts during the process. Of course, many exams require a cutscore to be set before it is published, which is impossible with the bookmark; the Angoff procedure is very useful then.
How do I implement the bookmark method?
The process of standard setting employing the Bookmark method consists of the following stages:
Identify a team of subject matter experts (SMEs); their number should be around 6-12, and led by a test developer/psychometrician/statistician
Create a list items according to item difficulty in an ascending order
Define the competency levels for test takers; for example, have the 6-12 experts discuss what should differentiate a “pass” candidate from a “fail” candidate
Experts read the items in the ascending order (they do not need to see the IRT values), and place a bookmark where appropriate based on professional judgement across well-defined levels
Calculate thresholds based on the bookmarks set, across all experts
If needed, discuss results and perform a second round
Example of the Bookmark Method
If there are four competency levels such as the NAEP example, then SMEs need to set up three bookmarks in-between: first bookmark is set after the last item in a row that fits the minimally competent candidate for the first level, then second and third. There are thresholds/cutscores from 1 to 2, 2 to 3, and 3 to 4. SMEs perform this individually without discussion, by reading the items.
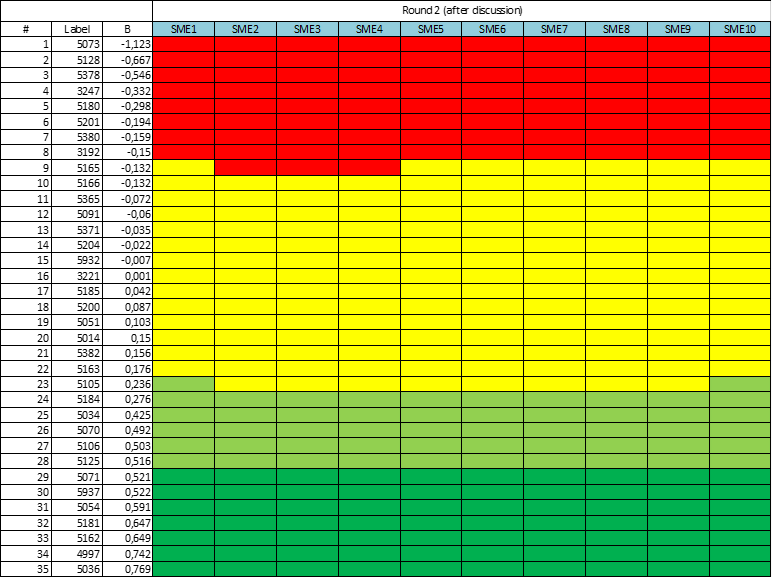
When all SMEs have provided their opinion, the standard setting coordinator combines all results into one spreadsheet and leads the discussion when all participants express their opinion referring to the bookmarks set. This might look like the sheet below. Note that SME4 had a relatively high standard in their mind, while SME2 had a low standard in their mind – placing virtually every student above an IRT score of 0.0 into the top category!
After the discussion, the SMEs are given one more opportunity to set the bookmarks again. Usually, after the exchange of opinions, the picture alters. SMEs gain consensus, and the variation in the graphic is reduced. An example of this is below.
What to do with the results?
Based on the SMEs’ voting results, the coordinator or psychometrician calculates the final thresholds on the IRT scale, and provides them to the analytical team who would ultimately prepare reports for the assessment across competency levels. This might entail score reports to examinees, feedback reports to teachers, and aggregate reports to test sponsors, government officials, and more.
You can see how the scientific approach will directly impact the interpretations of such reports. Rather than government officials just knowing how many students scored 80-90% correct vs 90-100% correct, the results are framed in terms of how many students are truly proficient in the topic. This makes decisions from test scores – both at the individual and aggregate levels – much more defensible and informative. They become truly criterion-referenced. This is especially true when the scores are equated across years to account for differences in examinee distributions and test difficulty, and the standard can be demonstrated to be stable. For high-stakes examinations such as medical certification/licensure, admissions exams, and many more situations, this is absolutely critical.
Want to talk to an expert about implementing this for your exams? Contact us.
References
[AERA, APA, & NCME] (American Educational Research Association, American Psychological Association, & National Council on Measurement in Education). (2014). Standards for educational and psychological testing. Washington, DC: American Educational Research Association.
Bejar, I. I. (2008). Standard setting: What is it? Why is it important. R&D Connections, 7, 1-6. Retrieved from https://www.ets.org/Media/Research/pdf/RD_Connections7.pdf
Buckendahl, C. W., Smith, R. W., Impara, J. C., & Plake, B. S. (2000). A comparison of Angoff and Bookmark standard setting methods. Paper presented at the Annual Meeting of the Mid-Western Educational Research Association, Chicago, IL: October 25-28, 2000.
Cizek, G., & Bunch, M. (2006). Standard Setting: A Guide to Establishing and Evaluating Performance Standards on Tests. Thousand Oaks, CA: Sage.
Cizek, G. J. (2007). Standard setting. In Steven M. Downing and Thomas M. Haladyna (Eds.) Handbook of test development. Mahwah, NJ: Lawrence Erlbaum Associates, Publishers, pp. 225-258.
Hambleton, R. K. (2013). Setting performance standards on educational assessments and criteria for evaluating the process. In Setting performance standards, pp. 103-130. Routledge. Retrieved from https://www.nciea.org/publications/SetStandards_Hambleton99.pdf
Karantonis, A., & Sireci, S. (2006). The Bookmark Standard‐Setting Method: A Literature Review. Educational Measurement Issues and Practice 25(1):4 – 12.
Lewis, D. M., Mitzel, H. C., & Green, D. R. (1996, June). Standard setting: A Book-mark approach. In D. R. Green (Chair),IRT-based standard setting procedures utilizing behavioral anchoring. Symposium conducted at the Council of Chief State School Officers National Conference on Large-Scale Assessment, Phoenix, AZ.
https://assess.com/wp-content/uploads/2021/10/bookmark-method-meeting-scaled.jpg17072560Laila Issayevahttps://assess.com/wp-content/uploads/2023/11/ASC-2022-Logo-no-tagline-300.pngLaila Issayeva2021-10-08 13:42:272023-11-14 05:58:02The Bookmark Method of Standard Setting
A test battery or assessment battery is a setmultiple psychometrically-distinct exams delivered in one administration. In some cases, these are various tests that are cobbled together for related purposes, such as a psychologist testing a 8 year old child on their intelligence, anxiety, and autism spectrum. However, in many cases it is a single test title that we often refer to as a single test but is actually several separate tests, like a university admissions test that has English, Math, and Logical Reasoning components. Why do so? The key here is that we want to keep them psychometrically separate, but maximize the amount of information about the person to meet the purposes of the test.
Test batteries are used in a variety of fields, pretty much anywhere assessment is done.
Admissions and Placement Testing
The classic example is a university admissions test that has English, Math, and Logic portions. These are separate tests, and psychometricians would calculate the reliability and other important statistics separately. However, the scores are combined at the end to get an overall picture of examinee aptitude or achievement, and use that to maximally predict 4-graduation rates and other important criterion variables.
Why is is called a battery? Because we are battering the poor student with not just one, but many exams!
Pre-Employment Testing
Exam batteries are often used in pre-employment testing. You might get tested on computer skills, numerical reasoning, and noncognitive traits such as integrity or conscientiousness. These are used together to gain incremental validity. A good example is the CAT-ASVAB, which is the selection test to get into the US Armed Forces. There are 10 tests (vocabulary, math, mechanical aptitude…).
Psychological or Psychoeducational Assessment
In a clinical setting, clinicians will often use a battery of tests, such as IQ, autism, anxiety, and depression. Some IQ tests themselves as a battery, as they might assess visual reasoning, logical reasoning, numerical reasoning, etc. However, these have a positive manifold, meaning that they correlate quite highly with each other. Another example is the Woodcock-Johnson.
K-12 Educational Assessment
Many large-scale tests that are used in schools are considered a battery, though often with only 2 or 3 aspects. A common one in the USA is the NWEA Measures of Academic Progress.
Composite Scores
A composite score is a combination of scores in a battery. If you took an admissions test like the SAT and GRE, you recall how it would add your scores on the different subtests, while the ACT test takes the average. The ASVAB takes a linear combination of the 4 most important subtests and uses them for admission; the others are used for job matching.
A Different Animal: Test with Sections
The battery is different than a single test that has distinct sections. For example, a K12 English test might have 10 vocab items, 10 sentence-completion grammar items, and 2 essays. Such tests are usually analyzed as a single test, as they are psychometrically unidimensional.
How to Deliver A Test Battery
In ASC’s platforms, Assess.ai and FastTest, all this functionality is available out of the box: test batteries, composite scores, and sections within a test. Moreover, they come with a lot of important functionality, such as separation of time limits, navigation controls, customizable score reporting, and more. Click here to request a free account and start applying best practices.
00Nathan Thompson, PhDhttps://assess.com/wp-content/uploads/2023/11/ASC-2022-Logo-no-tagline-300.pngNathan Thompson, PhD2021-10-06 20:24:542023-09-27 06:24:52What is an assessment / test battery?
The Test Response Function (TRF) in item response theory (IRT) is a mathematical function that describes the relationship between the latent trait that a test is measuring, which psychometricians call theta (θ), and the predicted raw score on the test in a traditional notion (percentage/proportion/number correct). An important concept from IRT, it provides a way to evaluate the performance of the test, as well as other aspects such as relative difficulty. In addition, it has more advanced usages, such as being used for some approaches to IRT equating.
What is the Test Response Function in IRT?
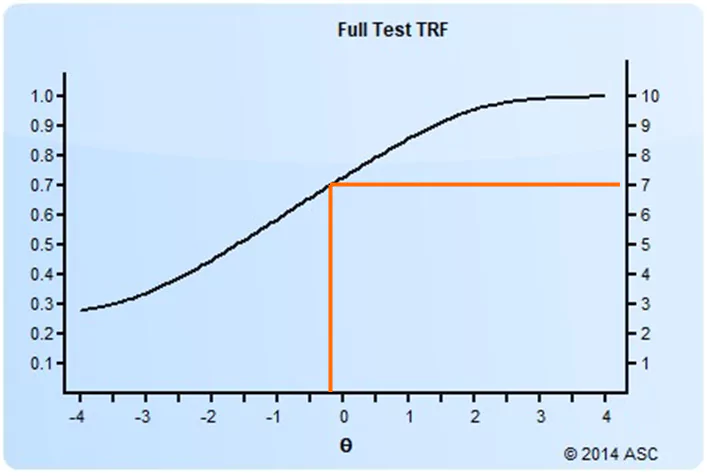
The test response function is a logistic-shaped curve like you see below. This is an example of a test with 10 dichotomous items. It tells us that a person with a theta of -0.30 is likely to get 7 items correct on the test, a proportion of 0.70. Meanwhile, an examinee with a theta of +2.0 is expected to get about 9.5 items correct on average. You can see how this provides some conceptual linkage between item response theory and classical test theory.
How do we determine the Test Response Function?
The test response function is obtained by summing the item response functions from all items in the test. Each item response function has a logistic shape as well, but the y-axis is the probability of getting a certain item correct and therefore ranges 0.0 to 1.0. So if you add these over 10 items, the raw range is then 0 to 10, as you see above.
Here is a brief example. Suppose you have a test of 5 items with the following IRT parameters.
Seq
a
b
c
1
0.80
-2.00
0.20
2
1.00
-1.00
0.00
3
0.70
0.00
0.25
4
1.20
0.00
0.25
5
1.10
1.00
0.20
The item response functions for these look like the graphic below. The dark blue line is the easiest item, and the light blue line is the hardest item.
If you sum up those IRFs, you would obtain this as the test response function. Note that the y-axis is now 5, because we have summed five 1-point items. It is telling us that a theta of -1.40 will likely get 2 items correct, and 0.60 get 4 items correct.
For completeness, also note that we can take the item information functions…
Note how these are all a function of each other, which is one of the strengths of item response theory. The last two are clearly an inverse of each other. The test response function is a function of the test information function if you consider the derivative. The TIF is a function of the derivative of the TRF, and therefore the TIF is highest where the TRF has the highest slope. The TRF usually has a high slope in the middle and less slope on the ends, so the TIF ends up being shaped like a mountain.
How can we use this to solve measurement issues?
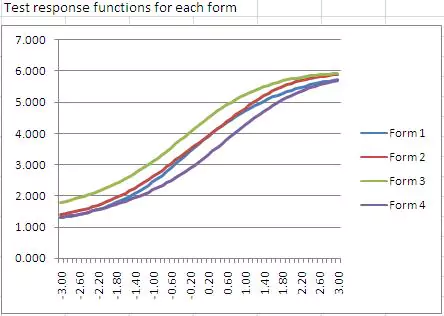
The test response function can be used to compare different test forms. The image below is from our Form Building Tool, and shows 4 test forms together. Form 3 is the easiest from a classical perspective, because it is higher than the rest for a given theta. That is, at a theta of 0.0, the expected score is 4.5, compared to 3.5 on forms 1 and 2, and 3.0 on Form 4. However, if you are scoring examinees with IRT, the actual form does not matter – such an examinee will receive a theta of 0.0 regardless of the form they take. (This won’t be exact for a test of 6 items… but for a test of 100 items it would work out.)
An important topic in psychometrics is Linking and Equating, that is, trying to determine comparable scores on different test forms. Two important methods for this, Stocking-Lord and Haebara, utilize the test response function in their calculations.
Generalizing the TRF to CAT and LOFT
Note that the TRF can be adapted by reconceptualizing the y-axis. Suppose we have a pool of 100 items and everyone will randomly receive 50, which is a form of linear on the fly testing (LOFT). The test response function with the scale of 0 to 100 is not as useful, but we can take the proportion scale and use that to predict raw scores out of 50 items, with some allowance for random variation. Of course, we could also use the actual 50 items that a given person saw to calculate the test response function for them. This could be compared across examinees to evaluate how equivalent the test forms are across examinees. In fact, some LOFT algorithms seek to maximize the equivalence of TRFs/TIFs across examinees rather than randomly selecting 50 items. The same can be said for computerized adaptive testing (CAT), but the number of items can vary between examinees with CAT.
OK, how do I actually apply this?
You will need software that can perform IRT calibrations, assemble test forms with IRT, and deliver tests that are scored with IRT. We provide all of this. Contact us to learn more.
00Nathan Thompson, PhDhttps://assess.com/wp-content/uploads/2023/11/ASC-2022-Logo-no-tagline-300.pngNathan Thompson, PhD2021-10-04 15:52:202023-10-01 04:53:44The Test Response Function in Item Response Theory
ASC’s CEO, Nathan Thompson PhD, was recently invited to speak on the SaaS Builders podcast hosted by Code Warriors. Listen to Dr. Thompson talk about ASC’s next-generation software for item banking, online testing, and psychometrics, and how stronger assessment software can impact just about any industry by improving what we know about people. ASC’s platforms allow organizations to develop and deliver stronger exams by leveraging concepts of artificial intelligence and automation, making psychometricians and test development staff more efficient. Modern methodologies such as computerized adaptive testing and item response theory are made more accessible by user-friendly interfaces and automated reports that explain deep psychometrics.
SaaS Builders is hosted by Jefferson Nunn, the CEO of Code Warriors and an expert in the development of SaaS products. The podcast is devoted to interviewing leaders from the SaaS world, helping others improve their own businesses and leadership skills.
Psychometric tests are assessments of people to measure psychological attributes such as personality or intelligence. Over the past century, psychometric tests have played an increasingly important part in revolutionizing how we approach important fields such as education, psychiatry, and recruitment. One of the main reasons why psychometric tests have become popular in corporate recruitment and education is their accuracy and objectivity.
However, getting the best out of psychometric tests requires one to have a concrete understanding of what they are, how they work, and why you need them. This article, therefore, aims to provide you with the fundamentals of psychometric testing, the benefits, and everything else you need to know.
Psychometrics refers to a field of study associated with the theory and technique of psychoeducational measurement. It is not limited to the topic of recruitment and careers, but spans all assessments, from K-12 formative assessment to addiction inventories in medical clinics to university admissions.
Interested in talking to a psychometrician about test development and validation, or a demo of our powerful assessment platform that empowers you to develop custom psychometric tests?
What is a psychometric test?
Psychometric tests are different from other types of tests in that they measure a person’s knowledge, abilities, interests, and other attributes. They focus on measuring “mental processes” rather than “objective facts.” Psychometric tests are used to determine suitability for employment, education, training, or placement, as well as the suitability of the person for specific situations.
A psychometric test or assessment is an evaluation of a candidate’s personality traits and cognitive abilities. They also help assess mental health status by screening the individual for potential mental disorders. In recruitment and job performance, companies use psychometric tests for reasons such as:
Make data-driven comparisons among candidates
Making leadership decisions
Reduce hiring bias and improve workforce diversification
Identify candidate strengths and weaknesses
Help complete candidate personas
Deciding management strategies
The different types of psychometric tests
The following are the main types of psychometric assessments;
Personality tests
Personality tests mainly help recruiters identify desirable personality traits that would make one fit for a certain role in a company. These tests contain a series of questions that measure and categorize important metrics such as leadership capabilities and candidate motivations as well as job-related traits such as integrity or conscientiousness. Some personality assessments seek to categorize people into relatively arbitrary “types” while some place people on a continuum of various traits.
‘Type focused’ Personality tests
Some examples of popular psychometric tests that use type theory include the Myers-Briggs Type Indicator (MBTI)and the DISC profile. Personality types are of limited usefulness in recruitment because they lack objectivity and reliability in determining important metrics that can predict the success of certain candidates in a specific role, as well as having more limited scientific backing. They are, to a large extent, Pop Psychology.
‘Trait-focused’ personality types
Personality assessments based on trait theory on the other hand tend to mainly rely on the OCEAN model, like theNEO-PI-R. These psychometric assessments determine the intensity of five traits; openness, conscientiousness, extraversion, agreeableness, and Neuroticism, using a series of questions and exercises. Psychometric assessments based on this model provide more insight into the ability of candidates to perform in a certain role, compared to type-focused assessments.
Cognitive Ability and Aptitude Tests
Cognitive ability tests, also known as intelligence tests or aptitude, measure a person’s latent/unlearned cognitive skills and attributes. Common examples of this are logical reasoning, numerical reasoning, and mechanical reasoning. It is important to stress that these are generally unlearned, as opposed to achievement tests.
Job Knowledge and Achievement tests
These psychometric tests are designed to assess what people have learned. For example, if you are applying for a job as an accountant, you might be given a numerical reasoning or logical reasoning test, and a test in the use of Microsoft Excel. The former is aptitude, while the latter is job knowledge or achievement. (Though there is certainly some learning involved with basic math skills).
What are the importance and benefits of psychometric tests?
Psychometric tests have been proven to be effective in domains such as recruitment and education. In recruitment, psychometric tests have been integrated into pre-employment assessment software because of their effectiveness in the hiring process. Here are several ways psychometric tests are beneficial in corporate environments, along with Learning and Development (L & D);
Cost and Time Efficiency- Psychometric tests save organizations a lot of resources because they help eliminate the guesswork in hiring processes. Psychometric tests help employers go through thousands of resumes to find the perfect candidates.
Cultural fulfillment- In the modern business world, culture is a great determinant of success. Through psychometric tests, employees can predict the types of candidates that can fit into their company culture.
Standardization- Traditional hiring processes have a lot of hiring bias cases. However, psychometric tests can level the playing ground and give a chance for the best candidates to get what they deserve.
Effectiveness– Psychometric tests have been scientifically proven to play a critical role in hiring the best talent. This is mainly because they can spot important attributes that can’t be spotted by traditional hiring processes.
In L&D, psychometric tests can help organizations generate important insights such as learning abilities, candidate strengths and weaknesses, and learning strategy effectiveness. This can help re-write the learning strategies, for improved ROI.
What makes a good psychometric test?
As with all tests, you need reliability and validity. In the case of pre-employment testing, the validity is usually one of two things:
Content validity via job-relatedness; if the job requires several hours per day of Microsoft Excel, then a test on Microsoft Excel makes sense
Predictive validity: numerical reasoning but not be as overtly related to the job as Microsoft Excel, but if you can show that it predicts job performance, then this is helpful. This is especially true for noncognitive assessments like conscientiousness.
Conclusion
There is no doubt that psychometric tests are important in essential aspects of life such as recruitment and education. Not only do they help us understand people, but also simplify the hiring process. However, psychometric tests should be used with caution. It’s advisable to develop a concrete strategy on how you are going to integrate them into your operation mechanism.
Ready To Start Developing Psychometric tests?
ASC’s comprehensive platform provides you with all the tools necessary to develop and securely deliver psychometric assessments. It is equipped with powerful psychometric software, online essay marking modules, advanced reporting, tech-enhanced items, and so much more! You also have access to the world’s greatest psychometricians to help you out if you get stuck in the process!
https://assess.com/wp-content/uploads/2013/12/Human-resources-director.jpg13221600Adminhttps://assess.com/wp-content/uploads/2023/11/ASC-2022-Logo-no-tagline-300.pngAdmin2021-10-01 00:08:362023-11-14 06:43:22What is a psychometric test?
The Rasch model, also known as the one-parameter logistic model, was developed by Danish mathematician Georg Rasch and published in 1960. Over the ensuing years it has attracted many educational measurement specialists and psychometricians because of its simplicity and ease of computational implementation. Indeed, since it predated the availability of computers for test development work, it was capable of being implemented using simple calculating equipment available at that time. The original model, developed for achievement and ability tests scored correct or incorrect, or for dichotomously scored personality or attitude scales, has since been extended into a family of models that work with polytomously scored data, rating scales, and a number of other measurement applications. The majority of those models maintain the simplicity of the original model proposed by Rasch.
In 1960, the Rasch model represented a step forward from classical test theory that had then been the major source of methods for test and scale development, and measuring individual differences, since the early 1900s. The model was accepted by some educational measurement specialists because of its simplicity, its relative ease of implementation, and most importantly because it maintained the use of the familiar number-correct score to quantify an individual’s performance on a test. Beyond serving as a bridge from classical test methods, the Rasch model is notable as the first formal statement of what, about ten years later, would be known as item characteristic curve theory or item response theory (IRT). As an IRT model, the Rasch model placed persons and items on the same scale, and introduced concepts such as item information, test information, conditional standard error of measurement, maximum likelihood estimation, and model fit.
What is the Rasch Model?
As an IRT model, the dichotomous Rasch model can be expressed as an equation,
This equation defines the item response function (or item characteristic curve) for a single test item. It states that the probability (pi) of a correct (or keyed) response (uij = 1) to an item (i), given a trait level (qj) for a person and the difficulty of an item (bj), is an exponential function of the difference between a person’s trait level and the difficulty of an item. If the difference between those two terms is zero, the probability is 0.50. If the person is “above” the item (the item is easy for the person) the probability is greater than 0.50; if the person is “below” the item (the item is difficult for the person) the probability will be less than .50. The probability correct, therefore, varies with the distance between the person and the item. This characteristic of the Rasch model is found, with some important modifications, in all later IRT models.
Assumptions of the Rasch Model
Based on the above equation, the Rasch model can be seen to make some strong assumptions. It obviously assumes that the only characteristic of test items that affects a person’s response to the item is its difficulty. But anyone who has ever done a classical item analysis has observed that items also vary in their discriminations—frequently markedly so. Yet the Rasch model ignores that information and assumes that all test items have a constant discrimination. Also, when used with multiple-choice items (or worse, true-false or other items with only two alternatives) guessing can also affect how examinees answer test items—yet the Rasch model also ignores guessing.
Because the model assumes that all items have the same discriminations, it allows examinees to be scored by number correct. But like classical test scoring methods using number-correct scores, their use results in a substantial loss of capability of reflecting individual differences among examinees by using number-correct scoring. For example, a 6-item number-correct scored test (too short to be useful) can make seven distinctions among a group of examinees, regardless of group size, whereas a more advanced IRT model can make 64 distinctions among those examinees by taking response pattern into account (i.e., which questions were answered correctly and which incorrectly); a 20-item test scored by number-correct results in 21 possible scores—again regardless of group size—whereas non-Rasch IRT scoring will result in 1,048,576 potentially different scores.
Perspectives on the Model
Although the Rasch model is the simplest case of more advanced IRT models, it incorporates a fundamental difference from its more realistic expansions—the two-, three- and four-parameter logistic (or normal ogive) models for dichotomously scored items. Applications of the Rasch model assume that the model is correct and that observed data must fit the model, Thus, items whose discriminations are not consistent with the model are eliminated in the construction of a measuring instrument. Similarly, in estimating latent trait scores for examinees, examinees whose responses do not fit the model are eliminated from the calibration data analysis. By contrast, the more advanced and flexible IRT models fit the model to the data. Although they evaluate model fit for each item (and similarly can evaluate it for each person) the model fit to a given dataset (whether it has two, three, or four item parameters) is the model that best fits that data. This philosophical—and operational—difference between the Rasch and the other IRT models has important practical implications for the outcome of the test development process.
The Rasch Model and other IRT Models
Although the Rasch model was an advancement is psychometrics in 1960, over the last 60 years it has been replaced by more general models that allow test items to vary in discrimination, guessing, and a fourth parameter. With the development of powerful computing capabilities, IRT has given rise to a wide-ranging family of models that function flexibly with ability, achievement, personality, attitude, and other educational and psychological variables. These IRT models are easily implemented with a variety of readily available software packages, and are based on models that can be fit to unidimensional or multidimensional datasets, model response times, and in many respects vastly improve the development of measuring instruments and measurement of individual differences. Given these advanced IRT models, the Rasch model can best be viewed as an early historical footnote in the history of modern psychometrics.
Implementing the Rasch Model
You will need specialized software. The most common is WINSTEPS. You might also be interested in Xcalibre (download trial version for free).