Classical Test Theory vs. Item Response Theory: What are some key differences, and how to choose?
Classical Test Theory and Item Response Theory (CTT & IRT) are the two primary psychometric paradigms. That is, they are mathematical approaches to how tests are analyzed and scored. They differ quite substantially in substance and complexity, even though they both nominally do the same thing. So how are they different, and how can you effectively choose the right solution? Let’s discuss.
First, let’s start by defining the two. This is just a brief intro; there are entire books dedicated to the details!
Classical test theory
Classical test theory (CTT) is an approach that is based on simple mathematics; primarily averages, proportions, and correlations. It is more than 100 years old, but is still used quite often, with good reason. In addition to working with small sample sizes, it is very simple and easy to understand, which makes it useful for working directly with content experts to evaluate, diagnose, and improve items or tests.
Item response theory (IRT) is a much more complex approach to analyzing tests. Moreover, it is not just for analyzing; it is a complete psychometric paradigm that changes how item banks are developed, test forms are designed, tests are delivered (adaptive or linear-on-the-fly), and scores produced. There are many benefits to this approach that justify the complexity, and there is good reason that all major examinations in the world utilize IRT. Learn more about IRT here.
How Classical Test Theory and Item Response Theory Differ
Test-Level and Subscore-Level Analysis
CTT statistics for total scores and subscores include coefficient alpha reliability, standard error of measurement (a function of reliability and SD), descriptive statistics (average, SD…), and roll-ups of item statistics (e.g., mean Rpbis).
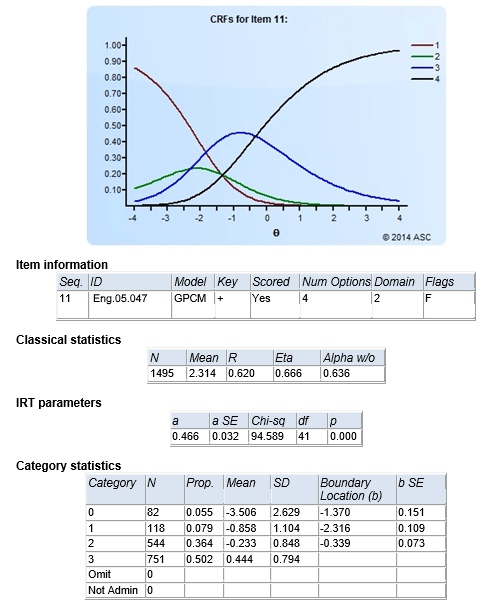
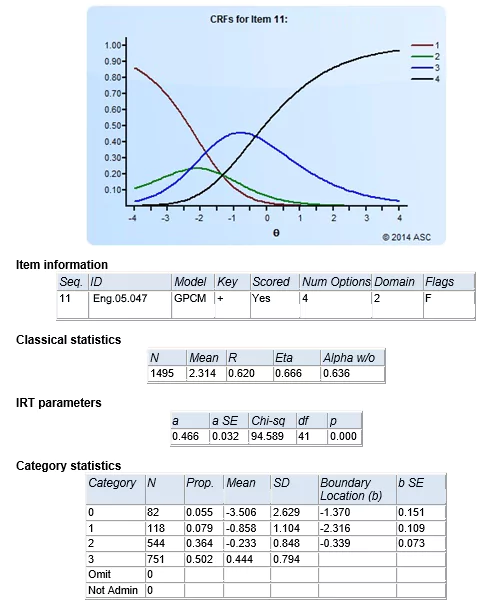
With IRT, we utilize the same descriptive statistics, but the scores are now different (theta, not number-correct). The standard error of measurement is now a conditional function, not a single number. The entire concept of reliability is dropped, and replaced with the concept of precision, and also as that same conditional function.
Item-Level Analysis
Item statistics for CTT include proportion-correct (difficulty), point-biserial (Rpbis) correlation (discrimination), and a distractor/answer analysis. If there is demographic information, CTT analysis can also provide a simple evaluation of differential item functioning (DIF).
IRT replaces the difficulty and discrimination with its own quantifications, called simply b and a. In addition, it can add a c parameter for guessing effects. More importantly, it creates entirely new classes of statistics for partial credit or rating scale items.
Scoring
CTT scores tests with traditional scoring: number-correct, proportion-correct, or sum-of-points. IRT scores examinees directly on a latent scale, which psychometricians call theta.
Linking and Equating
Linking and equating is a statistical analysis to determine comparable scores on different forms; e.g., Form A is “two points easier” than Form B and therefore a 72 on Form A is comparable to a 70 on Form B. CTT has several methods for this, including the Tucker and Levine methods, but there are methodological issues with these approaches. These issues, and other issues with CTT, eventually led to the development of IRT in the 1960s and 1970s.
One major advantage of IRT, as a corollary to the strong linking/equating, is that we can link/equate not just across multiple forms in one grade, but from grade to grade. This produces a vertical scale. A vertical scale can span across multiple grades, making it much easier to track student growth, or to measure students that are off-grade in their performance (e.g., 7th grader that is at a 5th grade level). A vertical scale is a substantial investment, but is extremely powerful for K-12 assessments.
Sample Sizes
Classical test theory can work effectively with 50 examinees, and provide useful results with as little as 20. Depending on the IRT model you select (there are many), the minimum sample size can be 100 to 1,000.
Sample- and Test-Dependence
CTT analyses are sample-dependent and test-dependent, which means that such analyses are performed on a single test form and set of students. It is possible to combine data across multiple test forms to create a sparse matrix, but this has a detrimental effect on some of the statistics (especially alpha), even if the test is of high quality, and the results will not reflect reality.
For example, if Grade 7 Math has 3 forms (beginning, middle, end of year), it is conceivable to combine them into one “super-matrix” and analyze together. The same is true if there are 3 forms given at the same time, and each student randomly receives one of the forms. In that case, 2/3 of the matrix would be empty, which psychometricians call sparse.
Distractor Analysis
Classical test theory will analyze the distractors of a multiple choice item. IRT models, except for the rarely-used Nominal Response Model, do not. So even if you primarily use IRT, psychometricians will also use CTT for this.
Guessing
Item response theory has a parameter to account for guessing, though some psychometricians argue against its use. Classical test theory has no effective way to account for guessing.
Adaptive Testing
There are rare cases where adaptive testing (personalized assessment) can be done with classical test theory. However, it pretty much requires the use of item response theory for one important reason: IRT puts people and items onto the same latent scale.
Linear Test Design
Classical Test Theory and Item Response Theory differ in how test forms are designed and built. Classical test theory works best when there are lots of items of middle difficulty, as this maximizes the coefficient alpha reliability. However, there are definitely situations where the purpose of the assessment is otherwise. IRT provides stronger methods for designing such tests, and then scoring as well.
So… How to Choose?
There is no single best answer to the question of Classical Test Theory vs. Item Response Theory. You need to evaluate the aspects listed above, and in some cases other aspects (e.g., financial, or whether you have staff available with the expertise in the first place). In many cases, BOTH are necessary. This is especially true because IRT does not provide an effective and easy-to-understand distractor analysis that you can use to discuss with subject matter experts. It is for this reason that IRT software will typically produce CTT analysis too, though the reverse is not true.
IRT is very powerful, and can provide additional information about tests if used just for analyzing results to evaluate item and test performance. However, IRT is really only useful if you are going to make it your psychometric paradigm, thereby using it in the list of activities above, especially IRT scoring of examines. Otherwise, IRT analysis is merely just another way of looking test and item performance that will correlate substantially with CTT.
https://assess.com/wp-content/uploads/2021/08/Classical-Test-Theory-vs.-Item-Response-Theory-scaled.jpg21242560Nathan Thompson, PhDhttps://assess.com/wp-content/uploads/2023/11/ASC-2022-Logo-no-tagline-300.pngNathan Thompson, PhD2021-08-31 13:58:512023-08-29 05:33:38Classical Test Theory vs. Item Response Theory
Paper-and-pencil testing used to be the only way to deliver assessments at scale. The introduction of computer-based testing (CBT) in the 1980s was a revelation – higher fidelity item types, immediate scoring & feedback, and scalability all changed with the advent of the personal computer and then later the internet. Delivery mechanisms including remote proctoringprovided students with the ability to take their exams anywhere in the world. This all exploded tenfold when the pandemic arrived. So why are some exams still offline, with paper and pencil?
Many education institutions are confused about which examination models to stick to. Should you go on with the online model they used when everyone was stuck in their homes? Should you adopt multi-modal examination models, or should you go back to the traditional pen-and-paper method?
This blog post will provide you with an evaluation of whether paper-and-pencil exams are still worth it in 2021.
Paper-and-pencil testing; The good, the bad, and the ugly
The Good
Offline exams have been a stepping stone towards the development of modern assessment models that are more effective. We can’t ignore the fact that there are several advantages of traditional exams.
Some advantages of paper-and-pencil testing include students having familiarity with the system, development of a social connection between learners, exemption from technical glitches, and affordability. Some schools don’t have the resources and pen-and-paper assessments are the only option available.
This is especially true in areas of the world that do not have the internet bandwidth or other technology necessary to deliver internet-based testing.
Another advantage of paper exams is that they can often work better for students with special needs, such as blind students which need a reader.
Paper and pencil testing is often more cost-efficient in certain situations where the organization does not have access to a professional assessment platform or learning management system.
The Bad and The Ugly
However, the paper-and-pencil testing does have a number of shortfalls.
1. Needs a lot of resources to scale
Delivery of paper-and-pencil testing at large scale requires a lot of resources. You are printing and shipping, sometimes with hundreds of trucks around the country. Then you need to get all the exams back, which is even more of a logistical lift.
2. Prone to cheating
Most people think that offline exams are cheat-proof but that is not the case. Most offline exams count on invigilators and supervisors to make sure that cheating does not occur. However, many pen-and-paper assessments are open to leakages. High candidate-to-ratio is another factor that contributes to cheating in offline exams.
3. Poor student engagement
We live in a world of instant gratification and that is the same when it comes to assessments. Unlike online exams which have options to keep the students engaged, offline exams are open to constant destruction from external factors.
Offline exams also have few options when it comes to question types.
4. Time to score
“To err is human.” But, when it comes to assessments, accuracy, and consistency. Traditional methods of hand-scoring paper tests are slow and labor-intensive. Instructors take a long time to evaluate tests. This defeats the entire purpose of assessments.
5. Poor result analysis
Pen-and-paper exams depend on instructors to analyze the results and come up with insight. This requires a lot of human resources and expensive software. It is also difficult to find out if your learning strategy is working or it needs some adjustments.
6. Time to release results
Online exams can be immediate. If you ship paper exams back to a single location, score them, perform psychometrics, then mail out paper result letters? Weeks.
7. Slow availability of results to analyze
Similarly, psychometricians and other stakeholders do not have immediate access to results. This prevents psychometric analysis, timely feedback to students/teachers, and other issues.
8. Accessibility
Online exams can be built with tools for zoom, color contrast changes, automated text-to-speech, and other things to support accessibility.
9. Convenience
Online tests are much more easily distributed. If you publish one on the cloud, it can immediately be taken, anywhere in the world.
10. Support for diversified question types
Unlike traditional exams which are limited to a certain number of question types, online exams offer many question types. Videos, audio, drag and drop, high-fidelity simulations, gamification, and much more are possible.
Sustainability is an important aspect of modern civilization. Online exams eliminate the need to use resources that are not environmentally friendly such as paper.
Conclusion
Is paper-and-pencil testing still useful? In most situations, it is not. The disadvantages outweigh the advantages. However, there are many situations where paper remains the only option, such as poor tech infrastructure.
Transitioning from paper-and-pencil testing to the cloud is not a simple task. That is why ASC is here to help you every step of the way, from test development to delivery. We provide you with the best assessment software and access to the most experienced team of psychometricians. Ready to take your assessments online?
The two terms Norm-Referenced and Criterion-Referenced are commonly used to describe tests, exams, and assessments. They are often some of the first concepts learned when studying assessment and psychometrics.
Norm-referenced means that we are referencing how your score compares to other people. Criterion-referenced means that we are referencing how your score compares to a criterion such as a cutscore or a body of knowledge.
Do we say a test is “Norm-Referenced” vs. “Criterion-Referenced”?
Actually, that’s a slight misuse.
The terms Norm-Referenced and Criterion-Referenced refer to score interpretations. Most tests can actually be interpreted in both ways, though they are usually designed and validated for only one of the other.
Hence the shorthand usage of saying “this is a norm-referenced test” even though it just means that it is the primarily intended interpretation.
Examples of Norm-Referenced vs. Criterion-Referenced
Suppose you received a score of 90% on a Math exam in school. This could be interpreted in both ways. If the cutscore was 80%, you clearly passed; that is the criterion-referenced interpretation. If the average score was 75%, then you performed at the top of the class; this is the norm-referenced interpretation. Same test, both interpretations are possible. And in this case, valid interpretations.
What if the average score was 95%? Well, that changes your norm-referenced interpretation (you are now below average) but the criterion-referenced interpretation does not change.
Now consider a certification exam. This is an example of a test that is specifically designed to be criterion-referenced. It is supposed to measure that you have the knowledge and skills to practice in your profession. It doesn’t matter whether all candidates pass or only a few candidates pass; the cutscore is the cutscore.
However, you could interpret your score by looking at your percentile rank compared to other examinees; it just doesn’t impact the cutscore
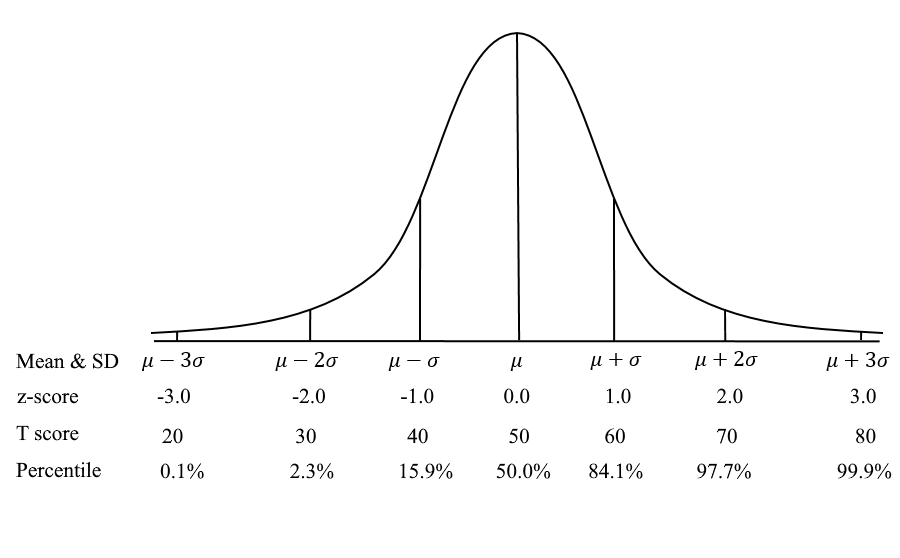
On the other hand, we have an IQ test. There is no criterion-referenced cutscore of whether you are “smart” or “passed.” Instead, the scores are located on the standard normal curve (mean=100, SD=15), and all interpretations are norm-referenced. Namely, where do you stand compared to others? The scales of the T score and z-score are norm-referenced, as are Percentiles. So are many tests in the world, like the SAT with a mean of 500 and SD of 100.
Is this impacted by item response theory (IRT)?
If you have looked at item response theory (IRT), you know that it scores examinees on what is effectively the standard normal curve (though this is shifted if Rasch). But, IRT-scored exams can still be criterion-referenced. It can still be designed to measure a specific body of knowledge and have a cutscore that is fixed and stable over time.
Even computerized adaptive testing can be used like this. An example is the NCLEX exam for nurses in the United States. It is an adaptive test, but the cutscore is -0.18 (NCLEX-PN on Rasch scale) and it is most definitely criterion-referenced.
Building and validating an exam
The process of developing a high-quality assessment is surprisingly difficult and time-consuming. The greater the stakes, volume, and incentives for stakeholders, the more effort that goes into developing and validating. ASC’s expert consultants can help you navigate these rough waters.
Want to develop smarter, stronger exams?
Contact us to request a free account in our world-class platform, or talk to one of our psychometric experts.
The item-total point-biserial correlation is a common psychometric index regarding the quality of a test item, namely how well it differentiates between examinees with high vs low ability.
What is item discrimination?
While the word “discrimination” has a negative connotation, it is actually a really good thing for an item to have. It means that it is differentiating between examinees, which is entirely the reason that an assessment item exists. If a math item on Fractions is good, then students with good knowledge of fractions will tend to get it correct, while students with poor knowledge will get it wrong. If this isn’t the case, and the item is essentially producing random data, then it has no discrimination. If the reverse is the case, then the discrimination will be negative. This is a total red flag; it means that good students are getting the item wrong and poor students are getting it right, which almost always means that there is incorrect content or the item is miskeyed.
What is the point-biserial correlation?
The point-biserial coefficient is a Pearson correlation between scores on the item (usually 0=wrong and 1=correct) and the total score on the test. As such, it is sometimes called an item-total correlation.
Consider the example below. There are 10 examinees that got the item wrong, and 10 that got it correct. The scores are definitely higher for the Correct group. If you fit a regression line, it would have a positive slope. If you calculated a correlation, it would be around 0.10.
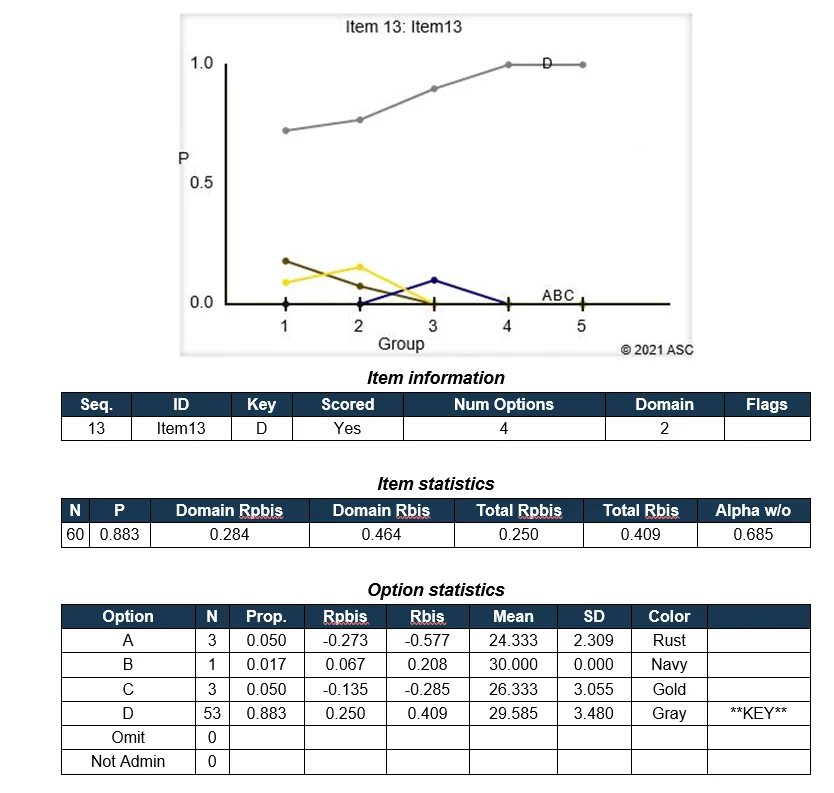
How do you calculate the point-biserial?
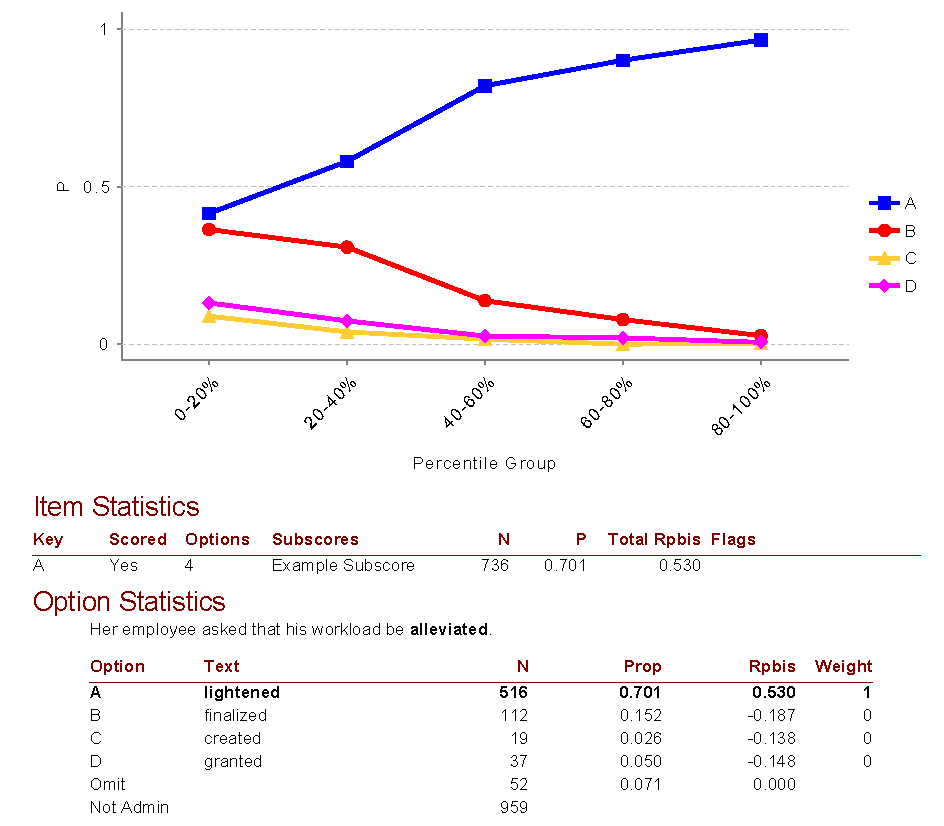
Since it is a Pearson correlation, you can easily calculate it with the CORREL function in Excel or similar software. Of course, psychometric software like Iteman will also do it for you, and many more important things besides (e.g., the point-biserial for each of the incorrect options!). This is an important step in item analysis. The image below is example output from Iteman, where Rpbis is the point-biserial. This item is very good, as it has a very high point-biserial for the correct answer and strongly negative point-biserials for the incorrect answers (which means the not-so-smart students are selecting them).
How do you interpret the point-biserial?
Well, most importantly consider the points above about near-zero and negative values. Besides that, a minimal-quality item might have a point-biserial of 0.10, a good item of about 0.20, and strong items 0.30 or higher. But, these can vary with sample size and other considerations. Some constructs are easier to measure than others, which makes item discrimination higher.
Are there other indices?
There are two other indices commonly used in classical test theory. There is the cousin of the point-biserial, the biserial. There is also the top/bottom coefficient, where the sample is split into a highly performing group and a lowly performing group based on total score, the P value calculated for each, and those subtracted. So if 85% of top examinees got it right and 60% of low examinees got it right, the index would be 0.25.
Of course, there is also the a parameter from item response theory. There are a number of advantages to that approach, most notably that the classical indices try to fit a linear model on something that is patently nonlinear. For more on IRT, I recommend a book like Embretson & Riese (2000).
The conditional standard error of measurement (CSEM) is a concept from psychometrics which seeks to characterize error in the process of measuring examinees on a test or assessment.
What is measurement error?
We can all agree that assessments are not perfect, from a 4th grade math quiz to a Psych 101 exam at university to a driver’s license test. Suppose you got 80% on an exam today. If we wiped your brain clean and you took the exam tomorrow, what score would you get? Probably a little higher or lower. Psychometricians consider you to have a true score which is what would happen if the test was perfect, you had no interruptions or distractions, and everything else fell into place. But in reality, you of course do not get that score each time. So psychometricians try to estimate the error in your score, and use this in various ways to improve the assessment and how scores are used.
The Original Approach: Classical Test Theory
Classical test theory (CTT) is a psychometric paradigm that is extremely useful in many situations, but generally oversimplifies things. Its approach to measurement error certainly qualifies. CTT assumes that measurement error – called the standard error of measurement – is the same for every examinee. It is calculated as SEM=SD*sqrt(1-r) where SD is the standard deviation of raw scores on the exam, and r is the reliability of the exam.
Why conditional standard error of measurement?
Early researchers realized that this assumption is unreasonable. Suppose that a test has a lot of easy questions. It will therefore measure low-ability examinees quite well. Imagine that it is a Math placement exam for university, and has a lot of Geometry and Algebra questions at a high school level. It will measure students well who are at that level, but do a very poor job of measuring good students.
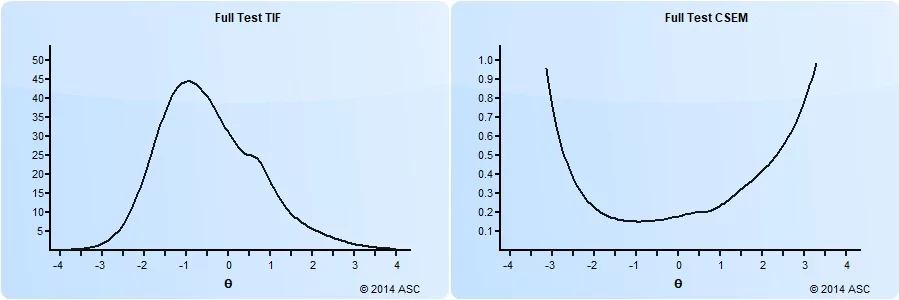
There was an initial suggestion of calculating a conditional standard error of measurement in classical test theory, but at that time, a new paradigm called item response theory was being developed. It considered error to be a function of ability, not a single number. In the previous example, the standard error for low students should be much less than the standard error for high students.
An example of this is shown below. On the right is the conditional standard error of measurement function, and on the left is its inverse, the test information function. Clearly, this test has a lot of items around -1.0 on the theta spectrum, which is around the 15th percentile. Students above 1.0 (85th percentile) are not being measured well.
How is CSEM used?
A useful way to think about conditional standard error of measurement is with confidence intervals. Suppose your score on a test is 0.5 with item response theory. If the CSEM is 0.25 (see above) then we can get a 95% confidence interval by taking plus or minus 2 standard errors. This means that we are 95% certain that your true score lies between 0.0 and 1.0. For a theta of 2.5 with an CSEM of 0.5, that band is then 1.5 to 2.5 – which might seem wide, but remember that is like 94th percentile to 99th percentile.
You will sometimes see scores reported in this manner. I once saw a report on an IQ test that did not give a single score, but instead said “we can expect that 9 times out of 10 that you would score between X and Y.”
There are various ways to use the CSEM and related functions in the design of tests, including the assembly of parallel linear forms and the development of computerized adaptive tests. To learn more about this, I recommend you delve into a book on IRT, such as Embretson and Riese (2000). That’s more than I can cover here.
00Nathan Thompson, PhDhttps://assess.com/wp-content/uploads/2023/11/ASC-2022-Logo-no-tagline-300.pngNathan Thompson, PhD2021-07-28 16:23:442023-09-27 07:16:46What is the conditional standard error of measurement (CSEM)?
The California Department of Human Resources (CalHR, calhr.ca.gov/) has selected Assessment Systems Corporation (ASC, assess.com) as its vendor for an online assessment platform. CalHR is responsible for the personnel selection and hiring of many job roles for the State, and delivers hundreds of thousands of tests per year to job applicants. CalHR seeks to migrate to a modern cloud-based platform that allows it to manage large item banks, quickly publish new test forms, and deliver large-scale assessments that align with modern psychometrics like item response theory (IRT) and computerized adaptive testing (CAT).
Assess.ai as a solution
ASC’s landmark assessment platform Assess.ai was selected as a solution for this project. ASC has been providing computerized assessment platforms with modern psychometric capabilities since the 1980s, and released Assess.ai in 2019 as a successor to its industry-leading platform FastTest. It includes modules for item authoring, item review, automated item generation, test publishing, online delivery, and automated psychometric reporting.
https://assess.com/wp-content/uploads/2021/07/CalHR-avatar.jpg9281170Nathan Thompson, PhDhttps://assess.com/wp-content/uploads/2023/11/ASC-2022-Logo-no-tagline-300.pngNathan Thompson, PhD2021-07-05 22:52:412023-10-12 23:28:24California Department of Human Resources Selects Assessment Systems Corporation as Vendor for Online Assessment Platform
Online proctoring software refers to platforms that proctor educational or professional assessments (exams or tests) when the proctor is not in the same room as the examinee. This means that it is done with a video stream or recording using a webcam and sometimes an additional device, which are monitored by a human and/or AI. It is also referred to as remote proctoring or invigilation. Online proctoring offers a compelling alternative to in-person proctoring, somewhere in between unproctored at-home tests and tests delivered at an expensive testing center in an office building. This makes it a perfect fit for medium-stakes exams, such as university placement, pre-employment screening, and many types of certification/licensure tests.
What are the types of online proctoring?
There are many types of online proctoring software on the market, spread across dozens of vendors, especially new ones that sought to capitalize on the pandemic which were not involved with assessment before hand. With so many options, how can you more effectively select amongst the types of remote proctoring? There are four types of remote proctoring platforms, which can be adapted to a particular use case, sometimes varying between different tests in a single organization. ASC supports all four types, and partners with 5 different vendors to help provide the best solution to our clients. In descending order of security:
Approach
What it entails for you
What it entails for the candidate
Live with professional proctors
You register a set of examinees in FastTest, and tell us when they are to take their exams and under what rules.
We provide the relevant information to the proctors.
You send all the necessary information to your examinees.
The most secure of the types of remote proctoring.
Examinee goes to ascproctor.com, where they will initiate a chat with a proctor.
After confirmation of their identity and workspace, they are provided information on how to take the test.
The proctor then watches a video stream from their webcam as well as a phone on the side of the room, ensuring that the environment is secure. They do not see the screen, so your exam content is not exposed. They maintain exam invigilation continuously.
When the examinee is finished, they notify the proctor, and are excused.
Live, bring your own proctor (BYOP)
You upload examinees into FastTest, which will generate links.
You send relevant instructions and the links to examinees.
Your staff logs into the admin portal and awaits examinees.
Videos with AI flagging are available for later review if needed.
Examinee will click on a link, which launches the proctoring software.
An automated system check is performed.
The proctoring is launched. Proctors ask the examinee to provide identity verification, then launch the test.
Examinee is watched on the webcam and screencast. AI algorithms help to flag irregular behavior.
Examinee concludes the test
Record and Review (with option for AI)
You upload examinees into FastTest, which will generate links.
You send relevant instructions and the links to examinees.
After examinees take the test, your staff (or ours) logs into review all the videos and report on any issues. AI will automatically flag irregular behavior, making your reviews more time-efficient.
Examinee will click on a link, which launches the proctoring software.
An automated system check is performed.
The proctoring is launched. System asks the examinee to provide identity verification, then launch the test.
Examinee is recorded on the webcam and screencast. AI algorithms help to flag irregular behavior.
Examinee concludes the test
AI only
You upload examinees into FastTest, which will generate links.
You send relevant instructions and the links to examinees.
Videos are stored for 1 month if you need to check any.
Examinee will click on a link, which launches the proctoring software.
An automated system check is performed.
The proctoring is launched. System asks the examinee to provide identity verification, then launch the test.
Examinee is recorded on the webcam and screencast. AI algorithms help to flag irregular behavior.
Examinee concludes the test
Some case studies for different types of exams
We’ve worked with all types of remote proctoring software, across many types of assessment:
ASC delivers high-stakes certification exams for a number of certification boards, in multiple countries, using the live proctoring with professional proctors. Some of these are available continuously on-demand, while others are on specific days where hundreds of candidates log in.
We partnered with a large university in South America, where their admissions exams were delivered using Bring Your Own Proctor, enabling them to drastically reduce costs by utilizing their own staff.
We partnered with a private company to provide AI-enhanced record-and-review proctoring for applicants, where ASC staff reviews the results and provides a report to the client.
We partner with an organization that delivers civil service exams for a country, and utilizes both unproctored and AI-only proctoring, differing across a range of exam titles.
Online Proctoring Software: Two Distinct Markets
First, I would describe the online proctoring industry as actually falling into two distinct markets, so the first step is to determine which of these fits your organization
Large scale, lower cost (when large scale), lower security systems designed to be used only as a plugin to major LMS platforms like Blackboard or Canvas. These systems are therefore designed for medium-stakes exams like an Intro to Psychology midterm at a university.
Lower scale, higher cost, higher security systems designed to be used with standalone assessment platforms. These are generally for higher-stakes exams like certification or workforce, or perhaps special use at universities like Admissions and Placement exams.
How to tell the difference? The first type will advertise about easy integration with systems like Blackboard or Canvas as a key feature. They will also often focus on AI review of videos, rather than using real humans. Another key consideration is to look at the existing client base, which is often advertised.
Other ways that online proctoring software can differ
Screen capture:
Some online proctoring providers have an option to record/stream the screen as well as the webcam. Some also provide the option to only do this (no webcam) for lower stakes exams.
Mobile phone as the second camera:
Some newer platforms provide the option to easily integrate the examinee’s mobile phone as a second camera (third stream, if you include screen capture), which effectively operates as a human proctor. Examinees will be instructed to use the video to show under the table, behind the monitor, etc., before starting the exam. They then might be instructed to stand up the phone 2 meters away with a clear view of the entire room while the test is being delivered. This is in addition to the webcam.
API integrations:
Some systems require software developers to set up an API integration with your LMS or assessment platform. Others are more flexible, and you can just log in yourself, upload a list of examinees, and you are all set.
On-Demand vs. Scheduled:
Some platforms involve the examinee scheduling a time slot. Others are purely on-demand, and the examinee can show up whenever they are ready. MonitorEDU is a prime example of this: examinees show up at any time, present their ID to a live human, and are then started on the test immediately – no downloads/installs, no system checks, no API integrations, nothing.
LMS systems rarely include any of this functionality, because they are not needed for a midterm exam of Intro to Psychology. However, most assessments in the world that have real stakes – university admissions, certifications, workforce hiring, etc. – depend heavily on such functionality. It’s not just out of habit or tradition, either. Such methods are considered essential by international standards including AERA/APA/NCMA, ITC, and NCCA.
ASC’s preferred online proctoring partners
ASC’s online assessment platforms are integrated with some of the leading remote proctoring software providers.
Type
Vendors
Live
MonitorEDU
AI
Alemira, Sumadi, ProctorFree
Record and Review
Alemira, ProctorFree
Bring Your Own Proctor
Alemira
List of Online Proctoring Software Providers
Looking to evaluate potential vendors? Here is a great place to start.
First, determine the level of security necessary, and the trade-off with costs. Live proctoring with professionals can cost $30 to $100 or more, while AI proctoring can be as little as a few dollars. Then, evaluate some vendors to see which group they fall into; note that some vendors can do all of them! Then, ask for some demos so you understand the business processes involved and the UX on the examinee side, both of which could substantially impact the soft costs for your organization. Then, start negotiating with the vendor you want!
Want some more information?
Get in touch with us, we’d love to show you a demo or introduce you to partners!
HR assessment software is everywhere, but there is a huge range in quality, as well as a wide range in the type of assessment that it is designed for.
HR assessment platforms help companies create effective assessments, thus saving valuable resources, improving candidate experience & quality, providing more accurate and actionable information about human capital, and reducing hiring bias. But, finding software solutions that can help you reap these benefits can be difficult, especially because of the explosion of solutions in the market. If you are lost on which tools will help you develop and deliver your own HR assessments, this guide is for you.
What is HR assessment?
There are various types of assessments used in HR. Here are four main areas, though this list is by no means exhaustive.
Pre-employment tests to select candidates
Post-training assessments
Certificate or certification exams (can be internal or external)
360-degree assessments and other performance appraisals
Pre-employment tests
Finding good employees in an overcrowded market is a daunting task. In fact, according to research by Career builder, 74% of employers admit to hiring the wrong employees. Bad hires are not only expensive, but can also adversely affect cultural dynamics in the workforce. This is one area where HR assessment software shows its value.
There are different types of pre-employment assessments. Each of them achieves a different goal in the hiring process. The major types of pre-employment assessments include:
Personality tests: Despite rapidly finding their way into HR, these types of pre-employment tests are widely misunderstood. Personality tests answer questions in the social spectrum. One of the main goals of these tests is to quantify the success of certain candidates based on behavioral traits.
Aptitude tests: Unlike personality tests or emotional intelligence tests which tend to lie on the social spectrum, aptitude tests measure problem-solving, critical thinking, and agility. These types of tests are popular because can predict job performance than any other type because they can tap into areas that cannot be found in resumes or job interviews.
Skills Testing: The kinds of tests can be considered a measure of job experience; ranging from high-end skills to low-end skills such as typing or Microsoft excel. Skill tests can either measure specific skills such as communication or measure generalized skills such as numeracy.
Emotional Intelligence tests: These kinds of assessments are a new concept but are becoming important in the HR industry. With strong Emotional Intelligence (EI) being associated with benefits such as improved workplace productivity and good leadership, many companies are investing heavily in developing these kinds of tests. Despite being able to be administered to any candidates, it is recommended they be set aside for people seeking leadership positions, or those expected to work in social contexts.
Risk tests: As the name suggests, these types of tests help companies reduce risks. Risk assessments offer assurance to employers that their workers will commit to established work ethics and not involve themselves in any activities that may cause harm to themselves or the organization. There are different types of risk tests. Safety tests, which are popular in contexts such as construction, measure the likelihood of the candidates engaging in activities that can cause them harm. Other common types of risk tests include Integrity tests.
Post-training assessments
This refers to assessments that are delivered after training. It might be a simple quiz after an eLearning module, up to a certification exam after months of training (see next section). Often, it is somewhere in between. For example you might take an afternoon sit through a training course, after which you take a formal test that is required to do something on the job. When I was a high school student, I worked in a lumber yard, and did exactly this to become an OSHA-approved forklift driver.
Certificate or certification exams
Sometimes, the exam process can be high-stakes and formal. It is then a certificate or certification, or sometimes a licensure exam. More on that here. This can be internal to the organization, or external.
Internal certification: The credential is awarded by the training organization, and the exam is specifically tied to a certain product or process that the organization provides in the market. There are many such examples in the software industry. You can get certifications in AWS, SalesForce, Microsoft, etc. One of our clients makes MRI and other medical imaging machines; candidates are certified on how to calibrate/fix them.
External certification: The credential is awarded by an external board or government agency, and the exam is industry-wide. An example of this is the SIE exams offered by FINRA. A candidate might go to work at an insurance company or other financial services company, who trains them and sponsors them to take the exam in hopes that the company will get a return by the candidate passing and then selling their insurance policies as an agent. But the company does not sponsor the exam; FINRA does.
360-degree assessments and other performance appraisals
Job performance is one of the most important concepts in HR, and also one that is often difficult to measure. John Campbell, one of my thesis advisors, was known for developing an 8-factor model of performance. Some aspects are subjective, and some are easily measured by real-world data, such as number of widgets made or number of cars sold by a car salesperson. Others involve survey-style assessments, such as asking customers, business partners, co-workers, supervisors, and subordinates to rate a person on a Likert scale. HR assessment platforms are needed to develop, deliver, and score such assessments.
HR Assessment Software: The Benefits
Now that you have a good understanding of what pre-employment tests are, let’s discuss the benefits of integrating pre-employment assessment software into your hiring process. Here are some of the benefits:
Saves Valuable resources
Unlike the lengthy and costly traditional hiring processes, pre-employment assessment software helps companies increase their ROI by eliminating HR snugs such as face-to-face interactions or geographical restrictions. Pre-employment testing tools can also reduce the amount of time it takes to make good hires while reducing the risks of facing the financial consequences of a bad hire.
Supports Data-Driven Hiring Decisions
Data runs the modern world, and hiring is no different. You are better off letting complex algorithms crunch the numbers and help you decide which talent is a fit, as opposed to hiring based on a hunch or less-accurate methods like an unstructured interview. Pre-employment assessment software helps you analyze assessments and generate reports/visualizations to help you choose the right candidates from a large talent pool.
Improving candidate experience
Candidate experience is an important aspect of a company’s growth, especially considering the fact that69% of candidates admitting not to apply for a job in a company after having a negative experience. Good candidate experience means you get access to the best talent in the world.
Elimination of Human Bias
Traditional hiring processes are based on instinct. They are not effective since it’s easy for candidates to provide false information on their resumes and cover letters. But, the use of pre-employment assessment software has helped in eliminating this hurdle. The tools have leveled the playing ground, and only the best candidates are considered for a position.
What To Consider When Choosing HR assessment software
Now that you have a clear idea of what pre-employment tests are and the benefits of integrating pre-employment assessment software into your hiring process, let’s see how you can find the right tools.
Here are the most important things to consider when choosing the right pre-employment testing software for your organization.
Ease-of-use
The candidates should be your top priority when you are sourcing pre-employment assessment software. This is because the ease of use directly co-relates with good candidate experience. Good software should have simple navigation modules and easy comprehension.
Here is a checklist to help you decide if a pre-employment assessment software is easy to use;
Are the results easy to interpret?
What is the UI/UX like?
What ways does it use to automate tasks such as applicant management?
Does it have good documentation and an active community?
Tests Delivery (Remote proctoring)
Good online assessment software should feature good online proctoring functionalities. This is because most remote jobs accept applications from all over the world. It is therefore advisable to choose a pre-employment testing software that has secure remote proctoring capabilities. Here are some things you should look for on remote proctoring;
Does the platform support security processes such as IP-based authentication, lockdown browser, and AI-flagging?
What types of online proctoring does the software offer? Live real-time, AI review, or record and review?
Does it let you bring your own proctor?
Does it offer test analytics?
Test & data security, and compliance
Defensibility is what defines test security. There are several layers of security associated with pre-employment test security. When evaluating this aspect, you should consider what pre-employment testing software does to achieve the highest level of security. This is because data breaches are wildly expensive.
The first layer of security is the test itself. The software should support security technologies and frameworks such as lockdown browser, IP-flagging, and IP-based authentication. If you are interested in knowing how to secure your assessments, learn more about it here.
The other layer of security is on the candidate’s side. As an employer, you will have access to the candidate’s private information. How can you ensure that your candidate’s data is secure? That is reason enough to evaluate the software’s data protection and compliance guidelines.
A good pre-employment testing software should be compliant with certifications such as GDRP. The software should also be flexible to adapt to compliance guidelines from different parts of the world.
Questions you need to ask;
What mechanisms does the software employ to eliminate infidelity?
Is their remote proctoring function reliable and secure?
Are they compliant with security compliance guidelines including ISO, SSO, or GDPR?
How does the software protect user data?
User experience
A good user experience is a must-have when you are sourcing any enterprise software. A new age pre-employment testing software should create user experience maps with both the candidates and employer in mind. Some ways you can tell if a software offers a seamless user experience includes;
User-friendly interface
Simple and easy to interact with
Easy to create and manage item banks
Clean dashboard with advanced analytics and visualizations
Customizing your user-experience maps to fit candidates’ expectations attracts high-quality talent.
With a single job post attracting approximately 250 candidates, scalability isn’t something you should overlook. A good pre-employment testing software should thus have the ability to handle any kind of workload, without sacrificing assessment quality.
It is also important you check the automation capabilities of the software. The hiring process has many repetitive tasks that can be automated with technologies such as Machine learning, Artificial Intelligence (AI), and robotic process automation (RPA).
Here are some questions you should consider in relation to scalability and automation;
Can it support candidates from different locations worldwide?
Reporting and analytics
A good pre-employment assessment software will not leave you hanging after helping you
develop and deliver the tests. It will enable you to derive important insight from the assessments.
The analytics reports can then be used to make data-driven decisions on which candidate is suitable and how to improve candidate experience. Here are some queries to make on reporting and analytics;
Does the software have a good dashboard?
What format are reports generated in?
What are some key insights that prospects can gather from the analytics process?
How good are the visualizations?
Customer and Technical Support
Customer and technical support is not something you should overlook. A good pre-employment assessment software should have an Omni-channel support system that is available 24/7. This is mainly because some situations need a fast response. Here are some of the questions your should ask when vetting customer and technical support;
What channels of support does the software offer/How prompt is their support?
How good is their FAQ/resources page?
Do they offer multi-language support mediums?
Do they have dedicated managers to help you get the best out of your tests?
Conclusion
Finding the right HR assessment software is a lengthy process, yet profitable in the long run. We hope the article sheds some light on the important aspects to look for when looking for such tools. Also, don’t forget to take a pragmatic approach when implementing such tools into your hiring process.
Are you stuck on how you can use pre-employment testing tools to improve your hiring process? Feel free to contact us and we will guide you on the entire process, from concept development to implementation. Whether you need off-the-shelf tests or a comprehensive platform to build your own exams, we can provide the guidance you need. We also offer free versions of our industry-leading software FastTest and Assess.ai– visit our Contact Us page to get started!
Assessment Systems Corporation (ASC; https://assess.com) announced today that Giulia Bianchi has joined the team as an Assessment Solutions Consultant. Giulia has a strong background in the assessment industry, with 6 years of experience in sales, marketing, and operations for International Testing and Training Services Ltd. Giulia helped grow ITTS from its infancy into a testing services provider with a network of more than 200 testing centers.
“I’m excited to have Giulia join our team, especially as we continue to grow our business during the COVID pandemic as test sponsors are searching for cost-effective solutions that allow them to quickly implement a digital transformation” says Nathan Thompson, PhD, the CEO of ASC. “In particular, I’m thrilled about Giulia’s experience in the assessment industry outside the US, and her multilingualism. She can help us to better serve our partners all across the world.”
Giulia is bilingual English/Italian, and also speaks French and Spanish. She is located in Europe and will focus on growing ASC’s presence there, by helping universities, pre-employment testing companies, language assessments, and other organizations to improve their assessments with modern psychometrics. ASC provides powerful software for online assessment and item banking, as well as consulting services to help organizations implement modern methods like item response theory and computerized adaptive testing.
For more information about ASC’s international partnerships, please contact us.
AI remote proctoring has seen an incredible increase of usage during the COVID pandemic. ASC works with a very wide range of clients, with a wide range of remote proctoring needs, and therefore we partner with a range of remote proctoring vendors that match to our clients’ needs, and in some cases bring on a new vendor at the request of a client.
At a broad level, we recommend live online proctoring for high-stakes exams such as medical certifications, and AI remote proctoring for medium-stakes exams such as pre-employment assessment. Suppose you have decided that you want to find a vendor for AI remote proctoring. How can you start evaluating solutions?
Well, it might be surprising, but even within the category of “AI remote proctoring” there can be substantial differences in the functionality provided, and you should therefore closely evaluate your needs and select the vendor that makes the most sense – which is the approach we at ASC have always taken.
How does AI remote proctoring work?
Because this approach is fully automated, we need to train machine learning models to look for things that we would generally consider to be a potential flag. These have to be very specific! Here are some examples:
Two faces in the screen
No faces in the screen
Voices detected
Black or white rectangle approximately 2-3 inches by 5 inches (phone is present)
Face looking away or down
White rectangle approximately 8 inches by 11 inches (notebook or extra paper is present)
These are continually monitored at each slice of time, perhaps twice per second. The video frames or still images are evaluated with machine learning models such as support vector machines to determine the probability that each flag is happening, and then an overall cheating score or probability is calculated. You can see this happening in real time at this very helpful video.
If you are a fan of the show Silicon Valley you might recall how a character built an app for recognizing food dishes with AI… and the first iteration was merely “hot dog” vs. “not hot dog.” This was a nod towards how many applications of AI break problems down into simple chunks.
Some examples of differences in AI remote proctoring
1. Video vs. Stills: Some vendors record full HD video of the student’s face with the webcam, while others are designed for lower-stakes exams, and only take a still shot every 10 seconds. In some cases, the still-image approach is better, especially if you are delivering exams in low-bandwidth areas.
2. Audio: Some vendors record audio, and flag it with AI. Some do not record audio.
3. Lockdown browser: Some vendors provide their own lockdown browser, such as Sumadi. Some integrate with market leaders like Respondus or SafeExam. Others do not provide this feature.
4. Peripheral detection: Some vendors can detect certain hardware situations that might be an issue, such as a second monitor. Others do not.
5. Second camera: Some vendors have the option to record a second camera; typically this is from the examinee’s phone, which is placed somewhere to see the room, since the computer webcam can usually only see their face.
6. Screen recording: Some vendors record full video of the examinee’s screen as they take the exam. It can be argued that this increases security, but is often not required if there is lockdown browser. It can also be argued that this decreases security, because now images of all your items reside in someplace other than your assessment platform.
7. Additional options: For example, Examus has a very powerful feature for Bring Your Own Proctors, where staff would be able to provide live online proctoring, enhanced with AI in real time. This would allow you to scale up the security for certain classifications that have high stakes but low volume, where live proctoring would be more appropriate.
Want some help in finding a solution?
We can help you find the right solution and implement it quickly for a sound, secure digital transformation of your assessments. Contact solutions@assess.com to request a meeting with one of our assessment consultants. Or, sign up for a free account in our assessment platforms, FastTest and Assess.ai and see how our Rapid Assessment Development (RAD) can get you up and running in only a few days. Remember that the assessment platform itself also plays a large role in security: leveraging modern methods like computerized adaptive testing or linear on-the-fly testing will help a ton.
What are current topics and issues regarding AI remote proctoring?
ASC hosted a webinar in August 2022, specifically devoted to this topic. You can view the video below.
https://assess.com/wp-content/uploads/2021/06/facial-recognition.png7341179Nathan Thompson, PhDhttps://assess.com/wp-content/uploads/2023/11/ASC-2022-Logo-no-tagline-300.pngNathan Thompson, PhD2021-05-17 00:27:312023-10-23 02:29:17AI Remote Proctoring: How To Choose A Solution