Automated item generation (AIG) is a paradigm for developing assessment items (test questions), utilizing principles of artificial intelligence and automation. As the name suggests, it tries to automate some or all of the effort involved with item authoring, as that is one of the most time-intensive aspects of assessment development – which is no news to anyone who has authored test questions!
Items can cost up to $2000 to develop, so even cutting the average cost in half could provide massive time/money savings to an organization. ASC provides AIG functionality, with no limits, to anyone who signs up for a free item banking account in our platform Assess.ai.
There are two types of automated item generation:
Type 1: Item Templates (Current Technology)
The first type is based on the concept of item templates to create a family of items using dynamic, insertable variables. There are three stages to this work. For more detail, read this article by Gierl, Lai, and Turner (2012).
- Authors, or a team, create an cognitive model by isolating what it is they are exactly trying to assess and different ways that it the knowledge could be presented or evidenced. This might include information such as what are the important vs. incidental variables, and what a correct answer should include .
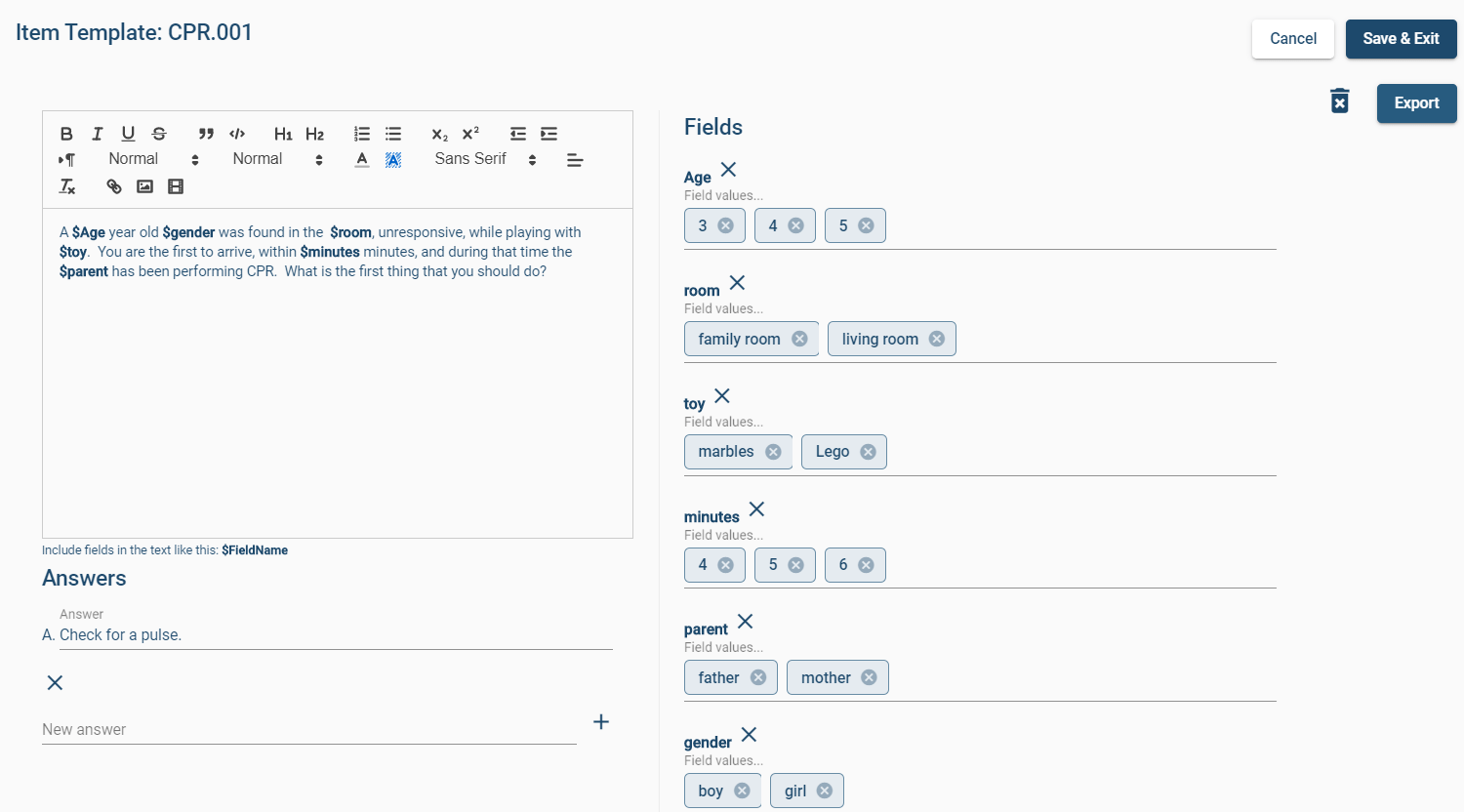
- They then develop templates for items based on this model, like the example you see below.
- An algorithm then turns this template into a family of related items, often by producing all possible permutations.
Obviously, you can’t use more than one of these on a given test form. And in some cases, some of the permutations will be an unlikely scenario or possibly completely irrelevant. But the savings can still be quite real. I saw a conference presentation by Andre de Champlain from the Medical Council of Canada, stating that overall efficiency improved by 6x and the generated items were higher quality than traditionally written items because the process made the authors think more deeply about what they were assessing and how. He also recommended that template permutations not be automatically moved to the item bank but instead that each is reviewed by SMEs, for reasons such as those stated above.
You might think “Hey, that’s not really AI…” – AI is doing things that have been in the past done by humans, and the definition gets pushed further every year. Remember, AI used to be just having the Atari be able to play Pong with you!
Type 2: AI Processing of Source Text (Future Technology)
The second type is what the phrase “automated item generation” more likely brings to mind: upload a textbook or similar source to some software, and it spits back drafts of test questions. For example, see this article by von Davier (2019). This technology is still cutting edge and working through issues. For example, how do you automatically come up with quality, plausible distractors for a multiple-choice item? This might be automated in some cases like mathematics, but in most cases, the knowledge of plausibility lies with content matter expertise. Moreover, this approach is certainly not accessible for the typical educator. It is currently in use, but by massive organizations that spend millions of dollars.
How Can I Implement Automated Item Generation?
AIG has been used the large testing companies for years but is no longer limited to their domain. It is now available off the shelf as part of ASC’s nextgen assessment platform, Assess.ai.
Assess.ai provides a clean, intuitive interface to implement Type 1 AIG, in a way that is accessible to all organizations. Develop your item templates, insert dynamic fields, and then export the results to review then implement in an item banking system, which is also available for free in Assess.ai.