The Frary, Tideman, and Watts (1977)g2 index is a collusion (cheating) detection index, which is a standardization that evaluates a number of common responses between two examinees in the typical standardized format: observed common responses minus the expectation of common responses, divided by the expected standard deviation of common responses. It compares all pairs of examinees twice: evaluating examinee copying off b and vice versa.
Frary, Tideman, and Watts (1977) g2 Index
The g2 collusion index starts by finding the probability, for each item, that the Copier would choose (based on their ability) the answer that the Source actually chose. The sum of these probabilities than the expected number of equivalent responses. We can then compare this to the actual observed number of equivalent responses and standardize that difference with the standard deviation. A very positive value could be possibly indicative of copying.
Where
Cab = Observed number of common responses (e.g., both examinees selected answer D)
k = number of items i
Uia = Random variable for examinee a’s response to item i
Xia = Observed response of examinee b to item i.
Frary et al. estimated P using classical test theory, and the definitions are provided in the original paper, while a slightly more clear definitions are provided in Khalid, Mehmood, and Rehman (2011).
The g2 approach produces two half-matrices, which SIFT presents as a single matrix separated by a blank diagonal. That is, the lower half of the matrix evaluates whether examinee a copied off b, and the upper half whether b copied off a. More specifically, the row number is the copier and the column number is the source. So Row1/Column2 evaluates whether 1 copied off 2, while Row2/Column1 evaluates whether 2 copied off 1.
For g2 and Wollack’s (1997) ω, the flagging procedure counts all values in the matrix greater than the critical value, so it is possible – likely actually – that each pair will be flagged twice. So the numbers in those flag total columns will be greater than those in the unidirectional indices.
How to interpret? This collusion index is standardized onto a z-metric, and therefore can easily be converted to the probability you wish to use. A standardized value of 3.09 is default for g2, ω, and Zjk because this translates to a probability of 0.001. A value beyond 3.09 then represents an event that is expected to be very rare under the assumption of no collusion.
Wollack (1997) adapted the standardized collusion index of Frary, Tidemann, and Watts (1977) g2 to item response theory (IRT) and produced the Wollack Omega (ω) index. It is clear that the graphics in the original article by Frary et al. (1977) were crude classical approximations of an item response function, so Wollack replaced the probability calculations from the classical approximations with those from IRT.
The probabilities could be calculated with any IRT model. Wollack suggested Bock’s Nominal Response Model since it is appropriate for multiple-choice data, but that model is rarely used in practice and very few IRT software packages support it. SIFT instead supports the use of dichotomous models: 1-parameter, 2-parameter, 3-parameter, and Rasch.
Because of using IRT, implementation of ω requires additional input. You must include the IRT item parameters in the control tab, as well as examinee theta values in the examinee tab. If any of that input is missing, the omega output will not be produced.
The ω index is defined as
Where P is the probability of an examinee with θa selecting the response, that examinee b selected, and cab is the RIC. That is, the probability that the copier with θa would select the responses that the source did when summed, this can be interpreted as the expected RIC.
Note: This uses all responses, not just errors.
How to interpret? The value will be higher when the copier had more responses in common with the source than we’d expect from a person of that (probably lower) ability. This index is standardized onto a z-metric, and therefore can easily be converted to the probability you wish to use.
A standardized value of 3.09 is the default for g2, ω, and Zjk because this translates to a probability of 0.001. A value beyond 3.09, then, represents an event that is expected to be very rare under the assumption of no collusion.
Wesolowsky’s (2000) index is a collusion detection index, designed to look for exam cheating by finding similar response vectors amongst examinees. It is in the same family as g2 and Wollack’s ω. Like those, it creates a standardized statistic by evaluating the difference between observed and expected common responses and dividing by a standard error. It is more similar to the g2 index in that it is based on classical test theory rather than item response theory. This has the advantage of being conceptually simpler as well as more feasible for small samples (it is well-known that IRT requires minimum sample sizes of 100 to 1000 depending on the model). However, this of course means that it lacks the conceptual, theoretical, and mathematical appropriateness of IRT, which is the dominant psychometric paradigm for large-scale tests for good reason.
Wesolowsky defined his collusion detection index as
where
Here, the expected number of common responses is equal to the joint probability of each examinee (j and k) getting item i correct, plus both getting it incorrect with the same distractor t selected. This is calculated as a single probability for each item then summed across items. The probability for each item is then of course multiplied by one minus itself to create a binomial variance.
The major difference between this and g2 is that g2 estimated the probability using a piecewise linear function that grossly approximated an item response function from IRT. Wesolowsky utilized a curvilinear function he called “iso-contours” which is better in that it is curvilinear, but it is still not on par with the item response function in terms of conceptual appropriateness. The iso-contours are described by a parameter Wesolowsky referred to as a (completely unrelated to the IRT discrimination parameter), which must be estimated by bisection approximation.
How to interpret? This index is standardized onto a z-metric, and therefore can easily be converted to the probability you wish to use. A standardized value of 3.09 is default for g2, ω, and Zjk because this translates to a probability of 0.001. A value beyond 3.09 then represents an event that is expected to be very rare under the assumption of no collusion.
Wise and Kong (2005) defined an index to flag examinees not putting forth minimal effort, based on their response time. It is called the response time effort (RTE) index. Let K be the number of items in the test. The RTE for each examinee j is
where TCji is 1 if the response time on item i exceeds some minimum cutpoint, and 0 if it does not.
How do I interpret Response Time Effort?
This therefore evaluates the proportion of items for which the examinee spent less time than the specified cutpoint, and therefore ranges from 0 to 1. You, as the researcher, needs to decide what that cutpoint is: 10 second, 30 seconds… what makes sense for your exam? It is then interpreted as an index of examinee engagement. If you think that each item should take at least 20 seconds to answer (perhaps an average of 45 seconds), and Examinee X took less than 20 seconds on half the items, then clearly they were flying through and not giving the effort that they should. Examinees could be flagged like this for removal from calibration data. You could even use this in real time, and put a message on the screen “Hey, stop slacking, and answer the questions!”
How do I implement RTE?
Want to calculate Response Time Effort on your data? Download the free software SIFT. SIFT provides comprehensive psychometric forensics, flagging examinees with potential issues such as poor motivation, stealing content, or copying amongst examinees.
The Holland K index and variants are probability-based indices for psychometric forensics, like the Bellezza & Bellezza indices, but make use of conditional information in their calculations. All three estimate the probability of observing wij or more identical incorrect responses (that is, EEIC, exact errors in common) between a pair of examinees in a directional fashion. This is defined as
.
Here, Ws is the number of items answered incorrectly by the source, Wcsis the EEIC, and Pr is the probability of the source and copier having the same incorrect response to an item. So, if the source had 20 items incorrect and the suspected copier had the same answer for 18 of them, we are calculating the probability of having 18 EEIC (the right side), then multiplying it by the number of ways there can be 18 EEICs in a set of 20 items (the middle). Finally, we do the same for 19 and 20 EEIC and sum up our three values. In this example, that would likely be summing three very small values because Pr is being taken to large powers and it is a probability such as 0.4. Such a situation would be very unlikely, so we’d expect a K index value of 0.000012.
If there were no cheating, the copier might have only 3 EEIC with the source, and we’d be summing from 3 up to 20, with the earlier values being relatively large. We’d likely then end up with a value of 0.5 or more.
The key number here is the Pr. The three variants of the K index differ in how it is calculated. Each of them starts by creating a raw frequency distribution of EEIC for a given source to determine an expected probability at a given “score group” r defined by the number of incorrect responses.
Here, MW refers to the mean number of EEIC for the score group and Ws is still the number of incorrect responses for the source.
The K index (Holland, 1996) uses this raw value. The K1 index applies linear regression to smooth the distribution, and the K2 index applies a quadratic regression to smooth it (Sotaridona & Meijer, 2002); because the regression-predicted value is then used, the notation becomes M-hat. Since these three then only differ by the amount of smoothing used in an intermediate calculation, the results will be extremely close to one another. This frequency distribution could be calculated based on only examinees in the same location, however, SIFT uses all examinees in the data set, as this would create a more conceptually appealing null distribution.
S1 and S2 apply the same framework of the raw frequency distribution of EEIC, but apply it to a different probability calculation instead of using a Poisson model:
.
S2 is often glossed over in publications as being similar, but it is much more complex. It contains the Poisson model but calculates the probability of the observed EEIC plus a weighted expectation of observed correct responses in common. This makes much more logical sense because many of the responses that a copier would copy from a smarter student will, in fact, be correct.
All the other K variants ignore this since it is so much harder to disentangle this from an examinee knowing the correct answer. Sotaridona and Meijer (2003), as well as Sotaridona’s original dissertation, provide treatment on how this number is estimated and then integrated into the Poisson calculations.
https://assess.com/wp-content/uploads/2020/07/Holland-K.png61268Nathan Thompson, PhDhttps://assess.com/wp-content/uploads/2023/11/ASC-2022-Logo-no-tagline-300.pngNathan Thompson, PhD2020-07-25 22:24:462020-07-25 22:24:46Holland K Index and K Variants for Psychometric Forensics
FastTest has been ASC’s flagship platform for the past 11 years, securely delivering millions of online exams powered with computerized adaptive testing and item response theory. FastTest is based on decades of experience in computerized test delivery and item banking, from MICROCAT in the 1980s to FastTest PC/LAN in the 1990s. And now the time has come for Fastest to be replaced with its own nextgen successor: Assess.ai.
With Assess.ai, we started by redesigning everything from the ground up, rather than just giving a facelift to FastTest. This leads to some differences in capability. Moreover, FastTest has seen more than 10 years of continuous development, so there is a massive amount of powerful functionality that has not yet been built into Assess.ai. So we’ve provided this guide to help you understand the advancements in Assess.ai and effectively select the right solution for your organization?
Will FastTest be riding into the proverbial sunset? Yes, but not anytime soon. For current users of FastTest, we’ll be working with you to guarantee a smooth transition.
Important differences between FastTest and Assess.ai
https://assess.com/wp-content/uploads/2020/06/Session-dashboard-with-widgets.png7641038Nathan Thompson, PhDhttps://assess.com/wp-content/uploads/2023/11/ASC-2022-Logo-no-tagline-300.pngNathan Thompson, PhD2020-06-02 19:39:362023-10-01 04:44:50What’s the difference between Assess.ai and FastTest?
A psychometrician is someone who practices psychometrics – the Science of Assessment. That is, they study the process of assessment development and validation itself, regardless of the type of assessment (certification, K-12, etc.). They are familiar with the scientific literature devoted to the development of fair, high-quality assessments, and they use this knowledge to improve assessments. Psychometricians learn about many different topics, and can take a number of slants, such as applied vs. academic, or quantitative vs. test development.
Also, in some parts of the world, the term psychometrician refers to someone who administers tests, typically in a counseling setting, and does not actually know anything about the development or validation of tests. That usage is incorrect; such a person is a psychometrist, as you can see at the website for the National Association of Psychometrists. Even major sites like ZipRecruiter don’t do the basic fact-checking to get this straight.
What does a psychometrician do?
There are many steps that go into developing a high quality, defensible assessment. These differ by the purpose of the test. When working on professional certifications or employment tests, a job analysis is typically necessary and is frequently done by a psychometrician. Yet job analysis totally irrelevant for K-12 formative assessments; the test is based on a curriculum, so a psychometrician’s time is spent elsewhere.
Some topics include:
Analyzing test data with item response theory or classical test theory to evaluate item performance
Linking and equating to determine comparability of test scores across different forms or years
This is a highly quantitative profession. Psychometricians spend most of their time working with datasets, using specially designed software or writing code in languages like R and Python.
A simple example of item analysis is shown below. This is an English vocabulary question. This question is extremely difficult; only 37% of students get it correct even though there is a 25% chance just by guessing. The item would probably be flagged for review. However, the point-biserial discrimination is extremely high, telling us that the item is actually very strong and defensible. Lots of students choose “confetti” but it is overwhelmingly the lower students, which is exactly what we want to have happen!
Where does a psychometrician work?
They work any place that develops high-quality tests. Some examples:
Large educational assessment organizations like ACT
Testing services companies like ASC; such companies provide psychometric services and software to organizations that cannot afford to hire their own fulltime psychometrician. This is often the case with certification and licensure boards.
What skills do I need?
There are two types of psychometrician: client-facing and data-facing. Though many psychometricians have skills in both domains.
Client-facing psychometricians excel in what one of my former employers called Client Engagements; parts of the process where you work directly with subject matter experts and stakeholders. Examples of this are job analysis studies, test design workshops, item writing workshops, and standard setting. All of these involve the use of an expert panel to discuss certain aspects. The skills you need here are soft skills; how to keep the SMEs engaged, meeting facilitation and management, explaining psychometric concepts to a lay person, and – yes – small talk during breaks!
Data-facing psychometricians focus on the numbers. Examples of this include equating, item response theory analysis, classical test theory reports, and adaptive testing algorithms. My previous employer called this the Client Reporting Team. The skills you need here are quite different, and center around data analysis and writing code.
How do I get a job as a psychometrician?
First, you need a graduate degree. In this field, a Master’s degree is considered entry-level, and a PhD is considered a standard level of education. It can often be in a related area like I/O psychology. Given that level of education, and the requirement for advanced data science skills, this career is extremely well-paid.
Wondering what kind of opportunities are out there? Check out the NCME Job Board and Horizon Search, a headhunter for assessment professionals.
Are all they created equal?
Absolutely not! Like any other profession, there are levels of expertise and skill. I liken it to top-level athletes: there are huge differences between what constitutes a good football/basketball/whatever player in high school, college, and the professional level. And the top levels are quite elite; many people who study psychometrics will never achieve them.
Personally, I group psychometricians into three levels:
Level 1: Practitioners at this level are perfectly comfortable with basic concepts and the use of classical test theory, evaluating items and distractors with P and Rpbis. They also do client-facing work like Angoff studies; many Level 2 and Level 3 psychometricians do not enjoy this work.
Level 2: Practitioners at this level are familiar with advanced topics like item response theory, differential item functioning, and adaptive testing. They routinely perform complex analyses with software such as Xcalibre.
Level 3: Practitioners at this level contribute to the field of psychometrics. They invent new statistics/algorithms, develop new software, publish books, start successful companies, or otherwise impact the testing industry and science of psychometrics in some way.
Note that practitioners can certainly be extreme experts in other areas: someone can be an internationally recognized expert in Certification Accreditation or Pre-Employment Selection but only be a Level 1 psychometrician because that’s all that’s relevant for them. They are a Level 3 in their home field.
Do these levels matter? To some extent, they are just my musings. But if you are hiring a psychometrician, either as a consultant or an employee, this differentiation is worth considering!
An item distractor, also known as a foil or a trap, is an incorrect option for a selected-response item on an assessment.
What makes a good item distractor?
One word: plausibility. We need the item distractor to attract examinees. If it is so irrelevant that no one considers it, then it does not do any good to include it in the item. Consider the following item.
What is the capital of the United States of America?
A. Los Angeles
B. New York
C. Washington, D.C.
D. Mexico City
The last option is quite implausible – not only is it outside the USA, but it mentions another country in the name, so no student is likely to select this. This then becomes a three-horse race, and students have a 1 in 3 chance of guessing. This certainly makes the item easier.
How much do distractors matter? Well, how much is the difficulty affected by this new set?
What is the capital of the United States of America?
A. Paris
B. Rome
C. Washington, D.C.
D. Mexico City
In addition, the distractor needs to have negative discrimination. That is, while we want the correct answer to attract the more capable examinees, we want the distractors to attract the lower examinees. If you have a distractor that you thought was incorrect, and it turns out to attract all the top students, you need to take a long, hard look at that question! To calculate discrimination statistics on distractors, you will need software such as Iteman.
What makes a bad item distractor?
Obviously, implausibility and negative discrimination are frequent offenders. But if you think more deeply about plausibility, the key is actually plausibility without being arguably correct. This can be a fine line to walk, and is a common source of problems for items. You might have a medical item that presents a scenario and asks for a likely diagnosis; perhaps one of the distractors is very unlikely so as to be essentially implausible, but it might actually be possible for a small subset of patients under certain conditions. If the author and item reviewers did not catch this, the examinees probably will, and this will be evident in the statistics. This is one of the reasons it is important to do psychometric analysis of test results; in fact, accreditation standards often require you to go through this process at least once a year.
Technology-enhanced items are assessment items (questions) that utilize technology to improve the interaction of the item, over and above what is possible with paper. Tech-enhanced items can improve examinee engagement (important with K12 assessment), assess complex concepts with higher fidelity, improve precision/reliability, and enhance face validity/sellability.
To some extent, the last word is the key one; tech-enhanced items simply look sexier and therefore make an assessment platform easier to sell, even if they don’t actually improve assessment. I’d argue that there are also technology-enabled items, which are distinct, as discussed below.
What is the goal of technology enhanced items?
The goal is to improve assessment, by increasing things like reliability/precision, validity, and fidelity. However, there are a number of TEIs that is actually designed more for sales purposes than psychometric purposes. So, how to know if TEIs improve assessment? That, of course, is an empirical question that is best answered with an experiment. But let me suggest one metric address this question: how far does the item go beyond just reformulating a traditional item format to use current user-interface technology? I would define the reformulating of traditional format to be a fake TEI while going beyond would define a true TEI.
An alternative nomenclature might be to call the reformulations technology-enhanced items and the true tech usage to be technology-enabled items (Almond et al, 2010; Bryant, 2017), as they would not be possible without technology.
A great example of this is the relationship between a traditional multiple response item and certain types of drag and drop items. There are a number of different ways that drag and drop items can be created, but for now, let’s use the example of a format that asks the examinee to drag text statements into a box.
An example of this is K12 assessment items from PARCC that ask the student to read a passage, then ask questions about it.
The item is scored with integers from 0 to K where K is the number of correct statements; the integers are often then used to implement the generalized partial credit model for final scoring. This would be true regardless of whether the item was presented as multiple response vs. drag and drop. The multiple response item, of course, could just as easily be delivered via paper and pencil. Converting it to drag and drop enhances the item with technology, but the interaction of the student with the item, psychometrically, remains the same.
Some True TEIs, or Technology Enabled Items
Of course, the past decade or so has witnessed stronger innovation in item formats. Gamified assessments change how the interaction of person and item is approached, though this is arguably not as relevant for high stakes assessment due to concerns of validity. There are also simulation items. For example, a test for a construction crane operator might provide an interface with crane controls and ask the examinee to complete a tasks. Even at the K-12 level there can be such items, such as the simulation of a science experiment where the student is given various test tubes or other instruments on the screen.
Both of these approaches are extremely powerful but have a major disadvantage: cost. They are typically custom-designed. In the case of the crane operator exam or even the science experiment, you would need to hire software developers to create this simulation. There are now some simulation-development ecosystems that make this process more efficient, but the items still involve custom authoring and custom scoring algorithms.
To address this shortcoming, there is a new generation of self-authored item types that are true TEIs. By “self-authored” I mean that a science teacher would be able to create these items themselves, just like they would a multiple choice item. The amount of technology leveraged is somewhere between a multiple choice item and a custom-designed simulation, providing a compromise of reduced cost but still increasing the engagement for the examinee. A major advantage of this approach is that the items do not need custom scoring algorithms, and instead are typically scored via point integers, which enables the use of polytomous item response theory.
Are we at least moving forward? Not always!
There is always pushback against technology, and in this topic the counterexample is the gridded item type. It actually goes in reverse of innovation, because it doesn’t take a traditional format and reformulate it for current UI. It actually ignores the capabilities of current UI (actually, UI for the past 20+ years) and is therefore a step backward. With that item type, students are presented a bubble sheet from a 1960s style paper exam, on a computer screen, and asked to fill in the bubbles by clicking on them rather than using a pencil on paper.
Another example is the EBSR item type from the artist formerly known as PARCC. It was a new item type that intended to assess deeper understanding, but it did not use any tech-enhancement or -enablement, instead asking two traditional questions in a linked manner. As any psychometrician can tell you, this approach ignored basic assumptions of psychometrics, so you can guess the quality of measurement that it put out.
How can I implement TEIs?
It takes very little software development expertise to develop a platform that supports multiple choice items. An item like the graphing one above, though, takes substantial investment. So there are relatively few platforms that can support these, especially with best practices like workflow item review or item response theory.
Automated item generation (AIG) is a paradigm for developing assessment items (test questions), utilizing principles of artificial intelligence and automation. As the name suggests, it tries to automate some or all of the effort involved with item authoring, as that is one of the most time-intensive aspects of assessment development – which is no news to anyone who has authored test questions!
Items can cost up to $2000 to develop, so even cutting the average cost in half could provide massive time/money savings to an organization. ASC provides AIG functionality, with no limits, to anyone who signs up for a free item banking account in our platform Assess.ai.
There are two types of automated item generation:
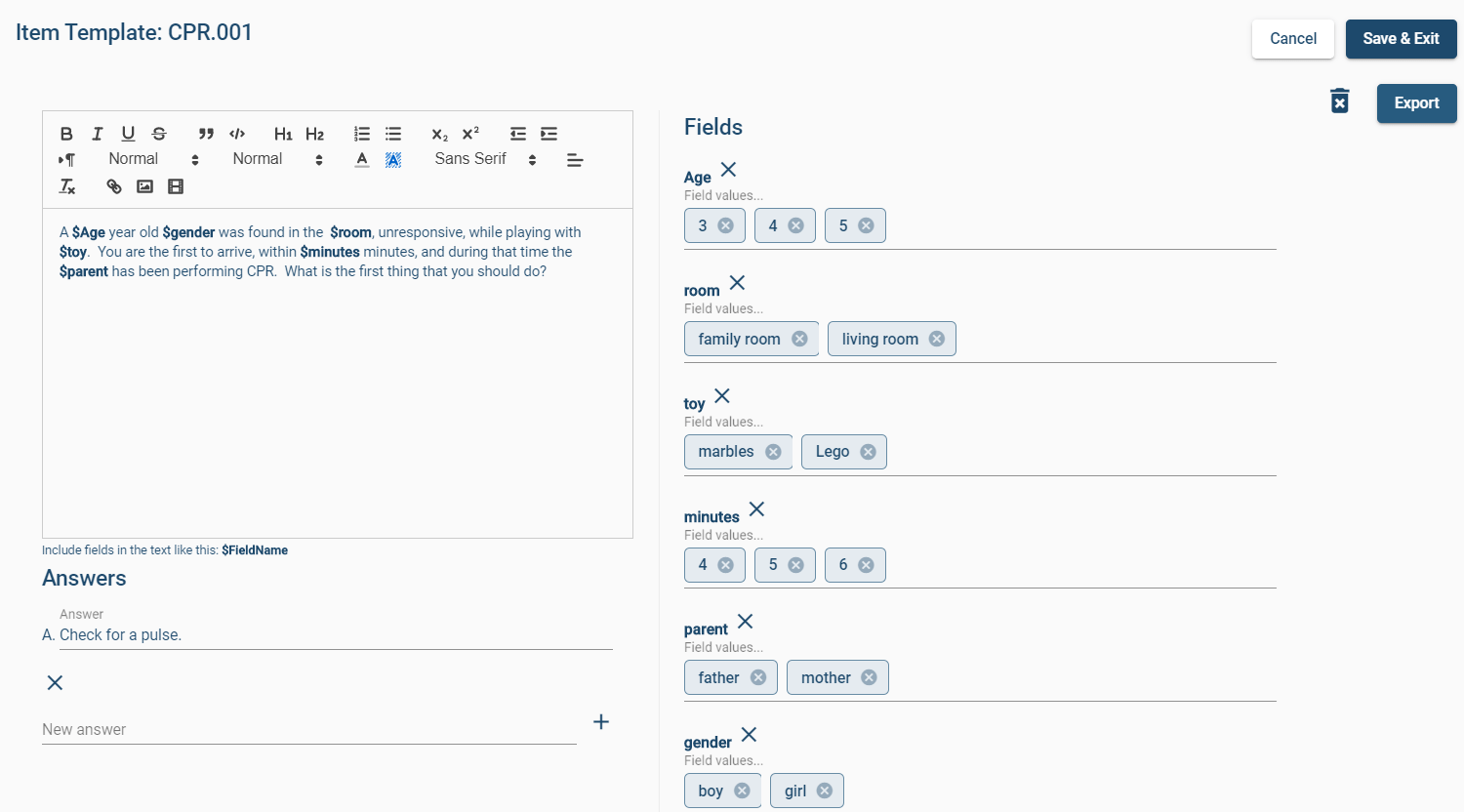
Type 1: Item Templates (Current Technology)
The first type is based on the concept of item templates to create a family of items using dynamic, insertable variables. There are three stages to this work. For more detail, read this article by Gierl, Lai, and Turner (2012).
Authors, or a team, create an cognitive model by isolating what it is they are exactly trying to assess and different ways that it the knowledge could be presented or evidenced. This might include information such as what are the important vs. incidental variables, and what a correct answer should include .
They then develop templates for items based on this model, like the example you see below.
An algorithm then turns this template into a family of related items, often by producing all possible permutations.
Obviously, you can’t use more than one of these on a given test form. And in some cases, some of the permutations will be an unlikely scenario or possibly completely irrelevant. But the savings can still be quite real. I saw a conference presentation by Andre de Champlain from the Medical Council of Canada, stating that overall efficiency improved by 6x and the generated items were higher quality than traditionally written items because the process made the authors think more deeply about what they were assessing and how. He also recommended that template permutations not be automatically moved to the item bank but instead that each is reviewed by SMEs, for reasons such as those stated above.
You might think “Hey, that’s not really AI…” – AI is doing things that have been in the past done by humans, and the definition gets pushed further every year. Remember, AI used to be just having the Atari be able to play Pong with you!
Type 2: AI Processing of Source Text (Future Technology)
The second type is what the phrase “automated item generation” more likely brings to mind: upload a textbook or similar source to some software, and it spits back drafts of test questions. For example, see this article by von Davier (2019). This technology is still cutting edge and working through issues. For example, how do you automatically come up with quality, plausible distractors for a multiple-choice item? This might be automated in some cases like mathematics, but in most cases, the knowledge of plausibility lies with content matter expertise. Moreover, this approach is certainly not accessible for the typical educator. It is currently in use, but by massive organizations that spend millions of dollars.
How Can I Implement Automated Item Generation?
AIG has been used the large testing companies for years but is no longer limited to their domain. It is now available off the shelf as part of ASC’s nextgen assessment platform, Assess.ai.
Assess.ai provides a clean, intuitive interface to implement Type 1 AIG, in a way that is accessible to all organizations. Develop your item templates, insert dynamic fields, and then export the results to review then implement in an item banking system, which is also available for free in Assess.ai.

 g2")