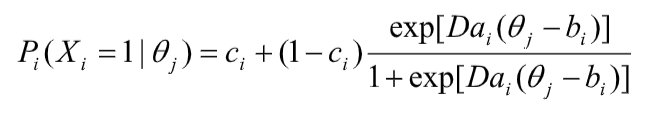If you have worked in the field of assessment and psychometrics, you have undoubtedly encountered the word “standard.” While a relatively simple word, it has the potential to be confusing because it is used in three (and more!) completely different but very important ways. Here’s a brief discussion.
Standard = Cutscore
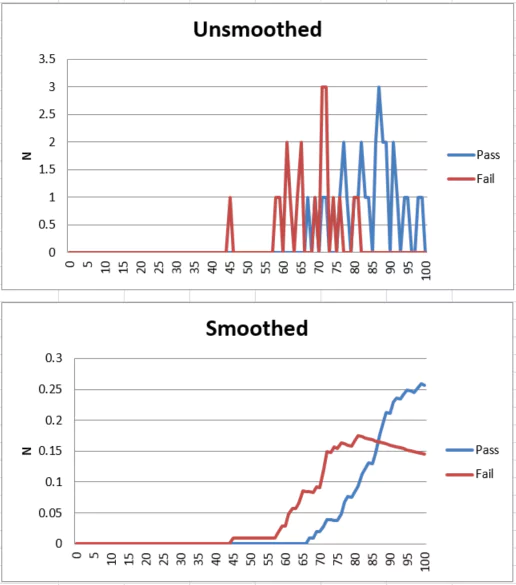
As noted by the well-known professor Gregory Cizek here, “standard setting refers to the process of establishing one or more cut scores on a test.” The various methods of setting a cutscore, like Angoff or Bookmark, are referred to as standard setting studies. In this context, the standard is the bar that separates a Pass from a Fail. We use methods like the ones mentioned to determine this bar in as scientific and defensible fashion as possible, and give it more concrete meaning than an arbitrarily selected round number like 70%. Selecting a round number like that will likely get you sued since there is no criterion-referenced interpretation.
Standard = Blueprint
If you work in the field of education, you often hear the term “educational standards.” These refer to the curriculum blueprints for an educational system, which also translate into assessment blueprints, because you want to assess what is on the curriculum. Several important ones in the USA are noted here, perhaps the most common of which nowadays is the Common Core State Standards, which attempted to standardize the standards across states. These standards exist to standardize the educational system, by teaching what a group of experts have agreed upon should be taught in 6th grade Math classes for example. Note that they don’t state how or when a topic should be taught, merely that 6th Grade Math should cover Number Lines, Measurement Scales, Variables, whatever – sometime in the year.
Standard = Guideline
If you work in the field of professional certification, you hear the term just as often but in a different context, accreditation standards. The two most common are the National Commission for Certifying Agencies (NCCA) and the ANSI National Accreditation Board (ANAB). These two organizations are a consortium of credentialing bodies that give a stamp of approval to credentialing bodies, stating that a Certification or Certificate program is legit. Why? Because there is no law to stop me from buying a textbook on any topic, writing 50 test questions in my basement, and selling it as a Certification. It is completely a situation of caveat emptor, and these organizations are helping the buyers by giving a stamp of approval that the certification was developed with accepted practices like a Job Analysis, Standard Setting Study, etc.
In addition, there are the professional standards for our field. These are guidelines on assessment in general rather than just credentialing. Two great examples are the AERA/APA/NCME Standards for Educational and Psychological Measurement and the International Test Commission’s Guidelines (yes they switch to that term) on various topics.
Also: Standardized = Equivalent Conditions
The word is also used quite frequently in the context of standardized testing, though it is rarely chopped to the root word “standard.” In this case, it refers to the fact that the test is given under equivalent conditions to provide greater fairness and validity. A standardized test does NOT mean multiple choice, bubble sheets, or any of the other pop connotations that are carried with it. It just means that we are standardizing the assessment and the administration process. Think of it as a scientific experiment; the basic premise of the scientific method is holding all variables constant except the variable in question, which in this case is the student’s ability. So we ensure that all students receive a psychometrically equivalent exam, with equivalent (as much as possible) writing utensils, scrap paper, computer, time limit, and all other practical surroundings. The problem comes with the lack of equivalence in access to study materials, prep coaching, education, and many bigger questions… but those are a societal issue and not a psychometric one.
So despite all the bashing that the term gets, a standardized test is MUCH better than the alternatives of no assessment at all, or an assessment that is not a level playing field and has low reliability. Consider the case of hiring employees: if assessments were not used to provide objective information on applicant skills and we could only use interviews (which are famously subjective and inaccurate), all hiring would be virtually random and the amount of incompetent people in jobs would increase a hundredfold. And don’t we already have enough people in jobs where they don’t belong?