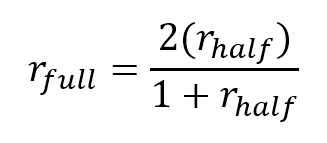Classical test theory is a century-old paradigm for psychometrics – using quantitative and scientific processes to develop and analyze assessments to improve their quality. (Nobody likes unfair tests!) The most basic and frequently used item statistic from classical test theory is the P-value. It is usually called item difficulty but is sometimes called item facility, which can lead to possible confusion.
The P-Value Statistic
The classical P-value is the proportion of examinees that respond correctly to a question, or respond in the “keyed direction” for items where the notion of correct is not relevant (imagine a personality assessment where all questions are Yes/No statements such as “I like to go to parties” … Yes is the keyed direction for an Extraversion scale). Note that this is NOT the same as the p-value that is used in hypothesis testing from general statistical methods. This P-value is almost universally agreed upon in terms of calculation. But some people call it item difficulty and others call it item facility. Why?
It has to do with the clarity interpretation. It usually makes sense to think of difficulty as an important aspect of the item. The P-value presents this, but in a reverse manner. We usually expect higher values to indicate more of something, right? But a P-value of 1.00 is high, and it means that there is not much difficulty; everyone gets the item correct, so it is actually no difficulty whatsoever. A P-value of 0.25 is low, but it means that there is a lot of difficulty; only 25% of examinees are getting it correct, so it has quite a lot of difficulty.
So where does “item facility” come in?
See how the meaning is reversed? It’s for this reason that some psychometricians prefer to call it item facility or item easiness. We still use the P-value, but 1.00 means high facility/easiness, and 0.25 means low facility/easiness. The direction of the semantics fits much better.
Nevertheless, this is a minority of psychometricians. There’s too much momentum to change an entire field at this point! It’s similar to the 3 dichotomous IRT parameters (a, b, c); some of you might have noticed that they are actually in the wrong order because the 1-parameter model does not use the parameter, it uses the b.
At the end of the day, it doesn’t really matter, but it’s another good example of how we all just got used to doing something and it’s now too far down the road to change it. Tradition is a funny thing.
https://assess.com/wp-content/uploads/2016/11/analytics-chart-80.png6461024Nathan Thompson, PhDhttps://assess.com/wp-content/uploads/2023/11/ASC-2022-Logo-no-tagline-300.pngNathan Thompson, PhD2018-10-28 15:21:532023-09-30 03:14:10What is the classical item facility statistic in psychometrics?
Cutscores set with classical test theory, such as the modified-Angoff method, Nedelsky, or Ebel methods, are easy to implement when the test is scored classically. The Angoff cutscore approach is legally defensible and meets international standards such as AERA/APA/NCME, ISO 17024, and NCCA. It also has the benefit that it does not require the test to be administered to a sample of candidates first; methods like Contrasting Groups, Borderline Group, and Bookmark do so.
But if your test is scored with the item response theory (IRT) paradigm, you need to convert your cutscores onto the theta scale. The easiest way to do that is to reverse-calculate the test response function (TRF) from IRT. This post will discuss that.
The Test Response Function
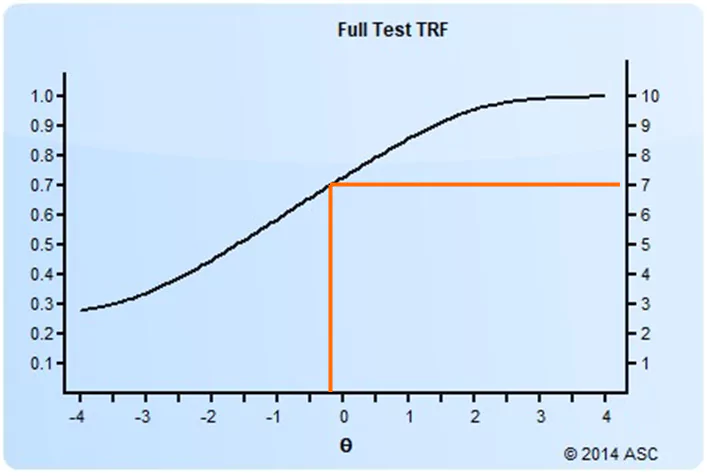
The TRF (sometimes called a test characteristic curve) is an important method of characterizing test performance in the IRT paradigm. The TRF predicts a classical score from an IRT score, as you see below. Like the item response function and test information function (item response and test information function ), it uses the theta scale as the X-axis. The Y-axis can be either the number-correct metric or proportion-correct metric.
In this example, you can see that a theta of -0.4 translates to an estimated number-correct score of approximately 7. Note that the number-correct metric only makes sense for linear or LOFT exams, where every examinee receives the same number of items. In the case of CAT exams, only the proportion correct metric makes sense.
Classical cutscore to IRT
So how does this help us with the conversion of a classical cutscore? Well, we hereby have a way of translating any number-correct score or proportion-correct score. So any classical cutscore can be reverse-calculated to a theta value. If your Angoff study (or Beuk) recommends a cutscore of 7 out of 10 points, you can convert that to a theta cutscore of -0.4 as above. If the recommended cutscore was 8, the theta cutscore would be approximately 0.7.
Because IRT works in a way that it scores examinees on the same scale with any set of items, as long as those items have been part of a linking/equating study. Therefore, a single study on a set of items can be equated to any other linear test form, LOFT pool, or CAT pool. This makes it possible to apply the classically-focused Angoff method to IRT-focused programs.
https://assess.com/wp-content/uploads/2018/08/Test-response-function-10-items-Angoff.jpg476707Nathan Thompson, PhDhttps://assess.com/wp-content/uploads/2023/11/ASC-2022-Logo-no-tagline-300.pngNathan Thompson, PhD2018-08-02 19:47:542023-11-14 06:44:55How to convert a classical cutscore to item response theory
Linear on the fly testing (LOFT) is an approach to assessment delivery that increases test security by limiting item exposure. It tries to balance the advantages of linear testing (e.g., everyone sees the same number of items, which feels fairer) with the advantages of algorithmic exams (e.g., creating a unique test for everyone).
In general, there are two families of test delivery. Static approaches deliver the same test form or forms to everyone; this is the ubiquitous and traditional “linear” method of testing. Algorithmic approaches deliver the test to each examinee based on a computer algorithm; this includes LOFT, computerized adaptive testing (CAT), and multistage testing (MST).
What is linear on-the-fly testing?
The purpose of linear on the fly testing is to give every examinee a linear form that is uniquely created for them – but each one is created to be psychometrically equivalent to all others to ensure fairness. For example, we might have a pool of 200 items, and every person only gets 100, but that 100 is balanced for each person. This can be done by ensuring content and/or statistical equivalency, as well ancillary metadata such as item types or cognitive level.
Content Equivalence
This portion is relatively straightforward. If your test blueprint calls for 20 items in each of 5 domains, for a total of 100 items, then each form administered to examinees should follow this blueprint. Sometimes the content blueprint might go 2 or even 3 levels deep.
Statistical Equivalence
There are, of course, two predominant psychometric paradigms: classical test theory (CTT) and item response theory (IRT). With CTT, forms can easily be built to have an equivalent P value, and therefore expected mean score. If point-biserial statistics are available for each item, you can also design the algorithm to design forms that have the same standard deviation and reliability.
With item response theory, the typical approach is to design forms to have the same test information function, or inversely, conditional standard error of measurement function. To learn more about how these are implemented, read this blog post about IRT or download our Classical Form Assembly Tool.
Implementing LOFT
LOFT is typically implemented by publishing a pool of items with an algorithm to select subsets that meet the requirements. Therefore, you need a psychometrically sophisticated testing engine that stores the necessary statistics and item metadata, lets you define a pool of items, specify the relevant options such as target statistics and blueprints, and deliver the test in a secure manner. Very few testing platforms can implement a quality LOFT assessment. ASC’s platform does; click here to request a demo.
Why all this?
It certainly is not easy to build a strong item bank, design LOFT pools, and develop a complex algorithm that meets the content and statistical balancing needs. So why would an organization use linear on the fly testing?
Well, it is much more secure than having a few linear forms. Since everyone receives a unique form, it is impossible for words to get out about what the first questions on the test are. And of course, we could simply perform a random selection of 100 items from a pool of 200, but that would be potentially unfair. Using LOFT will ensure the test remains fair and defensible.
Certification organizations that care about the quality of their examinations need to follow best practices and international standards for test development, such as the Standards laid out by the National Commission for Certifying Agencies (NCCA). One component of that is standard setting, also known as cutscore studies. One of the most common and respected approaches for that is the modified-Angoff methodology.
However, the Angoff approach has one flaw: the subject matter experts (SMEs) tend to expect too much out of minimally competent candidates, and sometimes set a cutscore so high that even they themselves would not pass the exam. There are several reasons this can occur. For example, raters might think “I would expect anyone that worked for me to know how to do this” and not consider the fact that people who work for them might have 10 years of experience while test candidates could be fresh out of training/school and have the topic only touched on for 5 minutes. SMEs often forget what it was like to be a much younger and inexperienced version of themselves.
For this reason, several compromise methods have been suggested to compare the Angoff-recommended cutscore with a “reality check” of actual score performance on the exam, allowing the SMEs to make a more informed decision when setting the official cutscore of the exam. I like to use the Beuk method and the Hofstee method.
The Hofstee Method
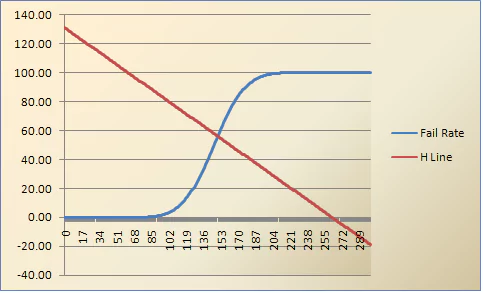
One method of adjusting the cutscore based on raters’ impressions of the difficulty of the test and possible pass rates is the Hofstee method (Mills & Melican, 1987; Cizek, 2006; Burr et al., 2016). This method requires the raters to estimate four values:
The minimum acceptable failure rate
The maximum acceptable failure rate
The minimum cutscore, even if all examinees failed
The maximum cutscore, even if all examinees passed
The first two values are failure rates, and are therefore between 0% and 100%, with 100% indicating a test that is too difficult for anyone to pass. The latter two values are on the raw score scale, and therefore range between 0 and the number of items in the test, again with a higher value indicating a more difficult cutscore to achieve.
These values are paired, and the line that passes through the two points estimated. The intersection of this line with the failure rate function, is the recommendation of the adjusted cutscore.
How can I use the Hofstee Method?
Unlike the Beuk, the Hofstee method does not utilize the Angoff ratings, so it represents a completely independent reality check. In fact, it is sometimes used as a standalone cutscore setting method itself, but because it does not involve rating of every single item, I recommend it be used in concert with the Angoff and Beuk approaches.
https://assess.com/wp-content/uploads/2018/05/Hofstee.png293483Nathan Thompson, PhDhttps://assess.com/wp-content/uploads/2023/11/ASC-2022-Logo-no-tagline-300.pngNathan Thompson, PhD2018-05-23 13:12:482023-09-22 05:21:37What is the Hofstee method for setting cutscores?
The Spearman-Brown formula, also known as the Spearman-Brown Prophecy Formula or Correction, is a method used in evaluating test reliability. It is based on the idea that split-half reliability has better assumptions than coefficient alpha but only estimates reliability for a half-length test, so you need to implement a correction that steps it up to a true estimate for a full-length test.
The most commonly used index of test score reliability is coefficient alpha. However, it’s not the only index on internal consistency. Another common approach is split-half reliability, where you split the test into two halves (first/last, even/odd, or random split) and then correlate scores on each. The reasoning is that if both halves of the test measure the same construct at a similar level of precision and difficulty, then scores on one half should correlate highly with scores on the other half. More information on split-half is found here.
However, split-half reliability provides an inconvenient situation: we are effectively gauging the reliability of half a test. It is a well-known fact that reliability is increased by more items (observations); we can all agree that a 100-item test is more reliable than a 10 item test comprised of similar quality items. So the split half correlation is blatantly underestimating the reliability of the full-length test.
The Spearman-Brown Formula
To adjust for this, psychometricians use the Spearman-Brown prophecy formula. It takes the split half correlation as input and converts it to an estimate of the equivalent level of reliability for the full-length test. While this might sound complex, the actual formula is quite simple.
As you can see, the formula takes the split half reliability (rhalf) as input and produces the full-length estimation (rfull) . This can then be interpreted alongside the ubiquitously used coefficient alpha.
While the calculation is quite simple, you still shouldn’t have to do it yourself. Any decent software for classical item analysis will produce it for you. As an example, here is the output of the Reliability Analysis table from our Iteman software for automated reporting and assessment intelligence with CTT. This lists the various split-half estimates alongside the coefficient alpha (and its associated SEM) for the total score as well as the domains, so you can evaluate if there are domains that are producing unusually unreliable scores.
Note: There is an ongoing argument amongst psychometricians whether domain scores are even worthwhile since the assumed unidimensionality of most tests means that the domain scores are less reliable estimates of the total score, but that’s a whole ‘another blog post!
Score
N Items
Alpha
SEM
Split-Half (Random)
Split-Half (First-Last)
Split-Half (Odd-Even)
S-B Random
S-B First-Last
S-B Odd-Even
All items
50
0.805
3.058
0.660
0.537
0.668
0.795
0.699
0.801
1
10
0.522
1.269
0.338
0.376
0.370
0.506
0.547
0.540
2
18
0.602
1.860
0.418
0.309
0.448
0.590
0.472
0.619
3
12
0.605
1.496
0.449
0.417
0.383
0.620
0.588
0.553
4
10
0.485
1.375
0.300
0.329
0.297
0.461
0.495
0.457
You can see that, as mentioned earlier, there are 3 ways to do the split in the first place, and Iteman reports all three. It then reports the Spearman-Brown formula for each. These generally align with the results of the alpha estimates, which overall provide a cohesive picture about the structure of the exam and its reliability of scores. As you might expect, domains with more items are slightly more reliable, but not super reliable since they are all less than 20 items.
So, what does this mean in the big scheme of things? Well, in many cases the Spearman-Brown estimates might not differ from the alpha estimates, but it’s still good to know that they do. In the case of high-stakes tests, you want to go through every effort you can to ensure that the scores are highly reliable and precise.
Artificial intelligence (AI) and machine learning (ML) have become buzzwords over the past few years. As I already wrote about, they are actually old news in the field of psychometrics. Factor analysis is a classical example of ML, and item response theory also qualifies as ML. Computerized adaptive testing is actually an application of AI to psychometrics that dates back to the 1970s.
One thing that is very different about the world of AI/ML today is the massive power available in free platforms like R, Python, and TensorFlow. I’ve been thinking a lot over the past few years about how these tools can impact the world of assessment. A straightforward application is too automated essay scoring; a common way to approach that problem is through natural language processing with the “bag of words” model and utilize the document-term matrix (DTM) as predictors in a model for essay score as a criterion variable. Surprisingly simple. This got me to wondering where else we could apply that sort of modeling. Obviously, student response data on selected-response items provides a ton of data, but the research questions are less clear. So, I turned to the topic that I think has the next largest set of data and text: item banks.
Step 1: Text Mining
The first step was to explore tools for text mining in R. I found this well-written and clear tutorial on the text2vec package and used that as my springboard. Within minutes I was able to get a document term matrix, and in a few more minutes was able to prune it. This DTM alone can provide useful info to an organization on their item bank, but I wanted to delve further. Can the DTM predict item quality?
Step 2: Fit Models
To do this, I utilized both the caret and glmnet packages to fit models. I love the caret package, but if you search the literature you’ll find it has a problem with sparse matrices, which is exactly what the DTM is. One blog post I found said that anyone with a sparse matrix is pretty much stuck using glmnet.
I tried a few models on a small item bank of 500 items from a friend of mine, and my adjusted R squared for the prediction of IRT parameters (as an index of item quality) was 0.53 – meaning that I could account for more than half the variance of item quality just by knowing some of the common words in each item’s stem. I wasn’t even using the answer texts n-grams, or additional information like Author and content domain.
Want to learn more about your item banks?
I’d love to swim even deeper on this issue. If you have a large item bank and would like to work with me to analyze it so you can provide better feedback and direction to your item writers and test developers, drop me a message at solutions@assess.com! This could directly impact the efficiency of your organization and the quality of your assessments.
So, yeah, the use of “hacks” in the title is definitely on the ironic and gratuitous side, but there is still a point to be made: are you making full use of current technology to keep your tests secure? Gone are the days when you are limited to linear test forms on paper in physical locations. Here are some quick points on how modern assessment technology can deliver assessments more securely, effectively, and efficiently than traditional methods:
1. AI delivery like CAT and LOFT
Psychometrics was one of the first areas to apply modern data science and machine learning (see this blog post for a story about a MOOC course). But did you know it was also one of the first areas to apply artificial intelligence (AI)? Early forms of computerized adaptive testing (CAT) were suggested in the 1960s and had become widely available in the 1980s. CAT delivers a unique test to each examinee by using complex algorithms to personalize the test. This makes it much more secure, and can also reduce test length by 50-90%.
2. Psychometric forensics
Modern psychometrics has suggested many methods for finding cheaters and other invalid test-taking behavior. These can range from very simple rules like flagging someone for having a top 5% score in a bottom 5% time, to extremely complex collusion indices. These approaches are designed explicitly to keep your test more secure.
3. Tech enhanced items
Tech enhanced items (TEIs) are test questions that leverage technology to be more complex than is possible on paper tests. Classic examples include drag and drop or hotspot items. These items are harder to memorize and therefore contribute to security.
4. IP address limits
Suppose you want to make sure that your test is only delivered in certain school buildings, campuses, or other geographic locations. You can build a test delivery platform that limits your tests to a range of IP addresses, which implements this geographic restriction.
5. Lockdown browser
A lockdown browser is a special software that locks a computer screen onto a test in progress, so for example a student cannot open Google in another tab and simply search for answers. Advanced versions can also scan the computer for software that is considered a threat, like a screen capture software.
6. Identity verification
Tests can be built to require unique login procedures, such as requiring a proctor to enter their employee ID and the test-taker to enter their student ID. Examinees can also be required to show photo ID, and of course, there are new biometric methods being developed.
7. Remote proctoring
The days are gone when you need to hop in the car and drive 3 hours to sit in a windowless room at a community college to take a test. Nowadays, proctors can watch you and your desktop via webcam. This is arguably as secure as in-person proctoring, and certainly more convenient and cost-effective.
So, how can I implement these to deliver assessments more securely?
Some of these approaches are provided by vendors specifically dedicated to that space, such as ProctorExam for remote proctoring. However, if you use ASC’s FastTest platform, all of these methods are available for you right out of the box. Want to see for yourself? Sign up for a free account!
Simulation studies are an essential step in the development of a computerized adaptive test (CAT) that is defensible and meets the needs of your organization or other stakeholders. There are three types of simulations: monte carlo, real data (post hoc), and hybrid.
Monte Carlo simulation is the most general-purpose approach, and the one most often used early in the process of developing a CAT. This is because it requires no actual data, either on test items or examinees – although real data is welcome if available – which makes it extremely useful in evaluating whether CAT is even feasible for your organization before any money is invested in moving forward.
Let’s begin with an overview of how Monte Carlo simulation works before we return to that point.
How a Monte Carlo Simulation works: An Overview
First of all, what do we mean by CAT simulation? Well, a CAT is a test that is administered to students via an algorithm. We can use that same algorithm on imaginary examinees, or real examinees from the past, and simulate how well a CAT performs on them.
Best of all, we can change the specifications of the algorithm to see how it impacts the examinees and the CAT performance.
Each simulation approach requires three things:
Item parameters from item response theory, though new CAT methods such as diagnostic models are now being developed
Examinee scores (theta) from item response theory
A way to determine how an examinee responds to an item if the CAT algorithm says it should be delivered to the examinee.
The monte Carlo simulation approach is defined by how it addresses the third requirement: it generates a response using some sort of mathematical model, while the other two simulation approaches look up actual responses for past examinees (real-data approach) or a mix of the two (hybrid).
The Monte Carlo simulation approach only uses the response generation process. The item parameters can either be from a bank of actual items or generated.
Likewise, the examinee thetas can be from a database of past data, or generated.
How does the response generation process work?
Well, it differs based on the model that is used as the basis for the CAT algorithm. Here, let’s assume that we are using the three-parameter logistic model. Start by supposing we have a fake examinee with a true theta of 0.0. The CAT algorithm looks in the bank and says that we need to administer item #17 as the first item, which has the following item parameters: a=1.0, b=0.0, and c=0.20.
Well, we can simply plug those numbers into the equation for the three-parameter model and obtain the probability that this person would correctly answer this item.
The probability, in this case, is 0.6. The next step is to generate a random number from the set of all real numbers between 0.0 and 1.0. If that number is less than the probability of correct response, the examinee “gets” the item correct. If greater, the examinee gets the item incorrect. Either way, the examinee is scored and the CAT algorithm proceeds.
For every item that comes up to be used, we utilize this same process. Of course, the true theta does not change, but the item parameters are different for each item. Each time, we generate a new random number and compare it to the probability to determine a response of correct or incorrect.
The CAT algorithm proceeds as if a real examinee is on the other side of the computer screen, actually responding to questions, and stops whenever the termination criterion is satisfied. However, the same process can be used to “deliver” linear exams to examinees; instead of the CAT algorithm selecting the next item, we just process sequentially through the test.
A road to research
For a single examinee, this process is not much more than a curiosity. Where it becomes useful is at a large scale aggregate level. Imagine the process above as part of a much larger loop. First, we establish a pool of 200 items pulled from items used in the past by your program. Next, we generate a set of 1,000 examinees by pulling numbers from a random distribution.
Finally, we loop through each examinee and administer a CAT by using the CAT algorithm and generating responses with the Monte Carlo simulation process. We then have extensive data on how the CAT algorithm performed, which can be used to evaluate the algorithm and the item bank. The two most important are the length of the CAT and its accuracy, which are a trade-off in most cases.
So how is this useful for evaluating the feasibility of CAT?
Well, you can evaluate the performance of the CAT algorithm by setting up an experiment to compare different conditions. Suppose you don’t have past items and are not even sure how many items you need? Well, you can create several different fake item banks and administer a CAT to the same set of fake examinees.
Or you might know the item bank to be used, but need to establish that a CAT will outperform the linear tests you currently use. There is a wide range of research questions you can ask, and since all the data is being generated, you can design a study to answer many of them. In fact, one of the greatest problems you might face is that you can get carried away and start creating too many conditions!
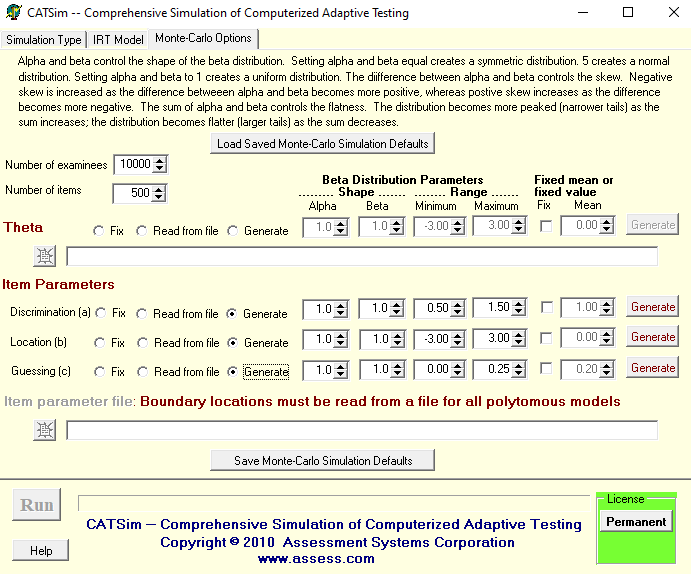
How do I actually do a Monte Carlo simulation study?
Fortunately, there is software to do all the work for you. The best option is CATSim, which provides all the options you need in a straightforward user interface (beware, this makes it even easier to get carried away). The advantage of CATSim is that it collates the results for you and presents most of the summary statistics you need without you having to calculate them. For example, it calculates the average test length (number of items used by a variable-length CAT), and the correlation of CAT thetas with true thetas. Other software exists which is useful in generating data sets using Monte Carlo simulation (see SimulCAT), but they do not include this important feature.
If you are involved with certification testing and are accredited by the National Commission of Certifying Agencies (NCCA), you have come across the term decision consistency. NCCA requires you to submit a report of 11 important statistics each year, each for all active test forms. These 11 provide a high level summary of the psychometric health of each form; more on that report here. One of the 11 is decision consistency.
What is Decision Consistency?
Decision consistency is an estimate of how consistent the pass/fail decision is on your test. That is, if someone took your test today, had their brain wiped of that memory, and took the test again next week, what is the probability that they would obtain the same classification both times? This is often estimated as a proportion or percentage, and we would of course hope that this number is high, but if the test is unreliable it might not be.
The reasoning behind the need for a index specifically on this is that the psychometric aspect we are trying to estimate is different than reliability of point scores (Moltner, Timbil, & Junger, 2015; Downing & Mehrens, 1978). The argument is that examinees near the cutscore are of interest, and reliability evaluates the entire scale. It’s for this reason that if you are using item response theory (IRT), the NCCA allows you to instead submit the conditional standard error of measurement function at the cutscore. But all of the classical decision consistency indices evaluate all examinees, and since most candidates are not near the cutscore, this inflates the baseline. Only the CSEM – from IRT – follows the line of reasoning of focusing on examinees near the cutscore.
An important distinction that stems from this dichotomy is that of decision consistency vs. accuracy. Consistency refers to receiving the same pass/fail classification each time if you take the test twice. But what we really care about is whether your pass/fail based on the test matches with your true state. For a more advanced treatment on this, I recommend Lathrop (2015).
Indices of Decision Consistency
There are a number of classical methods for estimating an index of decision consistency that have been suggested in the psychometric literature. A simple and classic approach is Hambleton (1972), which is based on an assumption that examinees actually take the same test twice (or equivalent forms). Of course, this is rarely feasible in practice, so a number of methods were suggested over the next few years on how to estimate this with a single test administration to a given set of examinees. These include Huynh (1976), Livingston (1972), and Subkoviak (1976). These are fairly complex. I once reviewed a report from a psychometrician that faked the Hambleton index because they didn’t have the skills to figure out any of the indices.
How does decision consistency relate to reliability?
The note I made above about unreliability is worth another visit, however. After the rash of publications on the topic, Mellenbergh and van der Linden (1978; 1980) pointed out that if you assume a linear loss function for misclassification, the conventional estimate of reliability – coefficient alpha – serves as a solid estimate of decision consistency. What is a linear loss function? It means that a misclassification is worse if the person’s score is further from the cutscore. That is, of the cutscore is 70, failing someone with a true score of 80 is twice as bad as failing someone with a true score of 75. Of course, we never know someone’s true score, so this is a theoretical assumption, but the researchers make an excellent point.
But while research amongst psychometricians on the topic cooled since they made that point, NCCA still requires one of the statistics -most from the 1970s – to be reported. The only other well-known index on the topic was Hanson and Brennan (1990). While the indices have been show to be different than classical reliability, I remain to be convinced that they are the right approach. Of course, I’m not much of a fan of classical test theory at all in the first place; that acceptance of CSEM from IRT is definitely aligned with my views on how psychometrics should tackle measurement problems.
The traditional Learning Management System (LMS) is designed to serve as a portal between educators and their learners. Platforms like Moodle are successful in facilitating cooperative online learning in a number of groundbreaking ways: course management, interactive discussion boards, assignment submissions, and delivery of learning content. While all of this is great, we’ve yet to see an LMS that implements best practices in assessment and psychometrics to ensure that medium or high stakes tests meet international standards.
To put it bluntly, LMS systems have assessment functionality that is usually good enough for short classroom quizzes but falls far short of what is required for a test that is used to award a credential. A white paper on this topic is available here, but some examples include:
Treatment of items as reusable objects
Item metadata and historical use
Collaborative item review and versioning
Test assembly based on psychometrics
Psychometric forensics to search for non-independent test-taking behavior
Deeper score reporting and analytics
Assessment Systems is pleased to announce the launch of an easy-to-use bridge between FastTest and Moodle that will allow users to seamlessly deliver sound assessments from within Moodle while taking advantage of the sophisticated test development and psychometric tools available within FastTest. In addition to seamless delivery for learners, all candidate information is transferred to FastTest, eliminating the examinee import process. The bridge makes use of the international Learning Tools Interoperability standards.
If you are already a FastTest user, watch a step-by-step tutorial on how to establish the connection, in the FastTest User Manual by logging into your FastTest workspace and selecting Manual in the upper right-hand corner. You’ll find the guide in Appendix N.
If you are not yet a FastTest user and would like to discuss how it can improve your assessments while still allowing you to leverage Moodle or other LMS systems for learning content, sign up for a free account here.