I often hear this question about scaling, especially regarding the scaled scoring functionality found in software like FastTest and Xcalibre. The following is adapted from lecture notes I wrote while teaching a course in Measurement and Assessment at the University of Cincinnati.
Test Scaling: Sort of a Tale of Two Cities
Scaling at the test level really has two meanings in psychometrics. First, it involves defining the method to operationally scoring the test, establishing an underlying scale on which people are being measured. It also refers to score conversions used for reporting scores, especially conversions that are designed to carry specific information. The latter is typically called scaled scoring.
You have all been exposed to this type of scaling, though you might not have realized it at the time. Most high-stakes tests like the ACT, SAT, GRE, and MCAT are reported on scales that are selected to convey certain information, with the actual numbers selected more or less arbitrarily. The SAT and GRE have historically had a nominal mean of 500 and a standard deviation of 100, while the ACT has a nominal mean of 18 and standard deviation of 6. These are actually the same scale, because they are nothing more than a converted z-score (standard or zed score), simply because no examinee wants to receive a score report that says you got a score of -1. The numbers above were arbitrarily selected, and then the score range bounds were selected based on the fact that 99% of the population is within plus or minus three standard deviations. Hence, the SAT and GRE range from 200 to 800 and the ACT ranges from 0 to 36. This leads to the urban legend of receiving 200 points for writing your name correctly on the SAT; again, it feels better for the examinee. A score of 300 might seem like a big number and 100 points above the minimum, but it just means that someone is in the 3rd percentile.
Now, notice that I said “nominal.” I said that because the tests do not actually have those means observed in samples, because the samples have substantial range restriction. Because these tests are only taken by students serious about proceeding to the next level of education, the actual sample is of higher ability than the population. The lower third or so of high school students usually do not bother with the SAT or ACT. So many states will have an observed average ACT of 21 and standard deviation of 4. This is an important issue to consider in developing any test. Consider just how restricted the population of medical school students is; it is a very select group.
How can I select a score scale?
For various reasons, actual observed scores from tests are often not reported, and only converted scores are reported. If there are multiple forms which are being equated, scaling will hide the fact that the forms differ in difficulty, and in many cases, differ in cutscore. Scaled scores can facilitate feedback. They can also help the organization avoid explanations of IRT scoring, which can be a headache to some.
When deciding on the conversion calculations, there are several important questions to consider.
First, do we want to be able to make fine distinctions among examinees? If so, the range should be sufficiently wide. My personal view is that the scale should be at least as wide as the number of items; otherwise you are voluntarily giving up information. This in turn means you are giving up variance, which makes it more difficult to correlate your scaled scores with other variables, like the MCAT is correlated with success in medical school. This, of course, means that you are hampering future research – unless that research is able to revert back to actual observed scores to make sure all information possible is used. For example, supposed a test with 100 items is reported on a 5-point grade scale of A-B-C-D-F. That scale is quite restricted, and therefore difficult to correlate with other variables in research. But you have the option of reporting the grades to students and still using the original scores (0 to 100) for your research.
Along the same lines, we can swing completely in the other direction. For many tests, the purpose of the test is not to make fine distinctions, but only to broadly categorize examinees. The most common example of this is a mastery test, where the examinee is being assessed on their mastery of a certain subject, and the only possible scores are pass and fail. Licensure and certification examinations are an example. An extension of this is the “proficiency categories” used in K-12 testing, where students are classified into four groups: Below Basic, Basic, Proficient, and Advanced. This is used in the National Assessment of Educational Progress (http://nces.ed.gov/nationsreportcard/). Again, we see the care taken for reporting of low scores; instead of receiving a classification like “nonmastery” or “fail,” the failures are given the more palatable “Below Basic.”
Another issue to consider, which is very important in some settings but irrelevant in others, is vertical scaling. This refers to the chaining of scales across various tests that are at quite different levels. In education, this might involve linking the scales of exams in 8th grade, 10th grade, and 12th grade (graduation), so that student progress can be accurately tracked over time. Obviously, this is of great use in educational research, such as the medical school process. But for a test to award a certification in a medical specialty, it is not relevant because it is really a one-time deal.
Lastly, there are three calculation options: pure linear (ScaledScore = RawScore * Slope + Intercept), standardized conversion (Old Mean/SD to New Mean/SD), and nonlinear approaches like Equipercentile.
Perhaps the most important issue is whether the scores from the test will be criterion-referenced or norm-referenced. Often, this choice will be made for you because it distinctly represents the purpose of your tests. However, it is quite important and usually misunderstood, so I will discuss this in detail.
Criterion-Referenced vs. Norm-Referenced
This is a distinction between the ways test scores are used or interpreted. A criterion-referenced score interpretation means that the score is interpreted with regards to defined content, blueprint, or curriculum (the criterion), and ignores how other examinees perform (Bond, 1996). A classroom assessment is the most common example; students are scored on the percent of items correct, which is taken to imply the percent of the content they have mastered. Conversely, a norm-referenced score interpretation is one where the score provides information about the examinee’s standing in the population, but no absolute (or ostensibly absolute) information regarding their mastery of content. This is often the case with non-educational measurements like personality or psychopathology. There is no defined content which we can use as a basis for some sort of absolute interpretation. Instead, scores are often either z-scores or some linear function of z-scores. IQ is historically scaled with a mean of 100 and standard deviation of 15.
It is important to note that this dichotomy is not a characteristic of the test, but of the test score interpretations. This fact is more apparent when you consider that a single test or test score can have several interpretations, some of which are criterion-referenced and some of which are norm-referenced. We will discuss this deeper when we reach the topic of validity, but consider the following example. A high school graduation exam is designed to be a comprehensive summative assessment of a secondary education. It is therefore specifically designed to cover the curriculum used in schools, and scores are interpreted within that criterion-referenced context. Yet scores from this test could also be used for making acceptance decisions at universities, where scores are only interpreted with respect to their percentile (e.g., accept the top 40%). The scores might even do a fairly decent job at this norm-referenced application. However, this is not what they are designed for, and such score interpretations should be made with caution.
Another important note is the definition of “criterion.” Because most tests with criterion-referenced scores are educational and involve a cutscore, a common misunderstanding is that the cutscore is the criterion. It is still the underlying content or curriculum that is the criterion, because we can have this type of score interpretation without a cutscore. Regardless of whether there is a cutscore for pass/fail, a score on a classroom assessment is still interpreted with regards to mastery of the content. To further add to the confusion, Industrial/Organizational psychology refers to outcome variables as the criterion; for a pre-employment test, the criterion is typically Job Performance at a later time.
This dichotomy also leads to some interesting thoughts about the nature of your construct. If you have a criterion-referenced score, you are assuming that the construct is concrete enough that anybody can make interpretations regarding it, such as mastering a certain percentage of content. This is why non-concrete constructs like personality tend to be only norm-referenced. There is no agreed-upon blueprint of personality.
Multidimensional Scaling
An advanced topic worth mentioning is multidimensional scaling (see Davison, 1998). The purpose of multidimensional scaling is similar to factor analysis (a later discussion!) in that it is designed to evaluate the underlying structure of constructs and how they are represented in items. This is therefore useful if you are working with constructs that are brand new, so that little is known about them, and you think they might be multidimensional. This is a pretty small percentage of the tests out there in the world; I encountered the topic in my first year of graduate school – only because I was in a Psychological Scaling course – and have not encountered it since.
Summary of test scaling
Scaling is the process of defining the scale that on which your measurements will take place. It raises fundamental questions about the nature of the construct. Fortunately, in many cases we are dealing with a simple construct that has a well-defined content, like an anatomy course for first-year medical students. Because it is so well-defined, we often take criterion-referenced score interpretations at face value. But as constructs become more complex, like job performance of a first-year resident, it becomes harder to define the scale, and we start to deal more in relatives than absolutes. At the other end of the spectrum are completely ephemeral constructs where researchers still can’t agree on the nature of the construct and we are pretty much limited to z-scores. Intelligence is a good example of this.
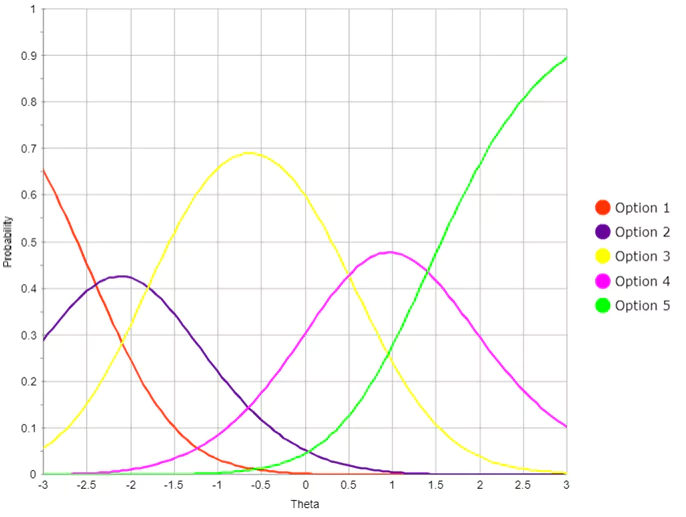
Some sources attempt to delineate the scaling of people and items or stimuli as separate things, but this is really impossible as they are so confounded. Especially since people define item statistics (the percent of people that get an item correct) and items define people scores (the percent of items a person gets correct). It is for this reason that IRT, the most advanced paradigm in measurement theory, was designed to place items and people on the same scale. It is also for this reason that item writing should consider how they are going to be scored and therefore lead to person scores. But because we start writing items long before the test is administered, and the nature of the construct is caught up in the scale, the issues presented here need to be addressed at the very beginning of the test development cycle.